|
|
SPEChpc Releases New v1.1 BenchmarkBy Mathew Colgrove, SPEC High Performance Group Release ManagerWith the release of the SPEChpc™ 2021 v1.0 benchmark last October, we have seen a great response from the HPC community. More than 100 institutions have received no-cost, non-commercial licenses, including large research facilities, universities, and even a few high schools. Beyond measuring performance of HPC systems, users have used SPEChpc benchmarks for educational purposes and installation testing, as well as to find node configuration issues, to name a few. Paraphrasing Nicole Hemsoth's The Next Platform article, SPEChpc is the benchmark real-world HPC deserves. SPEChpc benchmarks are ported to use multiple parallel models, MPI, OpenMP (using either host or target offload), and OpenACC, allowing for performance comparisons across a wide range of systems, including both homogeneous and heterogenous architectures. While porting applications to vendor-specific or language-specific parallel models may provide a better understanding of a system’s peak performance, the use of directive-based approaches, which are supported by multiple vendors, allows for better comparison of general performance. While v1.0 has been well received, a few users reported issues, so we are proud to announce the release of the SPEChpc v1.1 benchmark. While primarily a bug fix release, with the MPI and OpenMP host threaded results being comparable to v1.0, we did find a few performance problems with the OpenACC and OpenMP Target Offload versions. Hence, take care when comparing v1.0 results using these models. The full list of changes can be found at: https://www.spec.org/hpc2021/Docs/changes-in-v1.1.html. To upgrade to the SPEChpc v1.1 benchmark, current users can contact the SPEC Office at info@spec.org or use runhpc's update feature. New users, qualified non-commercial academic and research institutions can apply for a no-cost license. Commercial users may purchase the SPEChpc benchmark. The SPEC/HPG Release Manager (me) did make a slight error in v1.0, where I missed changing the update version. Hence, to use the runhpc update feature, please do the following.
Note that the system does need a direct internet connection to perform the update. You can confirm the update by viewing the 'version.txt' file, which should say '1.1.7'. SPEChpc Weak ScalingThe current SPEChpc benchmark workloads are strong scaled, i.e., time to solution of a fixed-size workload. As more system resources are added (in our case more MPI ranks), with perfect scaling, the time solution would decrease proportional to added resources. However, elements such as fixed overhead and MPI communication will eventually reduce scaling efficiency until the point when adding more resources no longer improves performance. 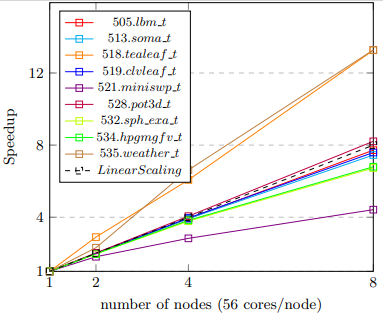  To help with scaling, the SPEChpc benchmark includes four separate workloads, one for each Suite: Tiny, Small, Medium, and Large, each progressively larger than the next. As one workload reaches the top of the scaling curve, the next larger workload can be used. However, even the Large workload will eventually reach the top of curve and the SPEChpc benchmark can’t be effectively used past this point. The exact point at which this occurs varies widely by the system in use, with denser compute nodes, such as those with attached acceleration devices, reaching the top with far fewer ranks. While strong scaling is an important aspect of system scaling, SPEC/HPG is currently developing a complimentary weak scaling benchmark. Users will be asked to provide the workload size to use, tailoring the size to their system. However, given the workload size will be variable, time to solution can no longer be used as the metric. Instead, weak scaling will use a throughput metric, a figure of merit (FOM), measuring the amount of work performed over a fixed amount time. The exact FOM used will be determined by the individual benchmark, but an example would be the number of ray traces computed per second. Not all applications are capable of weak scaling, including about half of the current SPEChpc benchmarks. Hence, SPEC/HPG has introduced the SPEChpc Weak Scaling Search Program asking you to submit your applications as candidate benchmarks for this new suite. The search program includes an award of up to $5000 as an appreciation of your contribution. Applications can come from any domain but should be HPC focused. Full applications are encouraged, but often mini apps work better. Candidates are preferred to not have library dependencies, but accommodations can be made for portable libraries, such as HDF5 or NetCDF. While the candidates will eventually be ported by SPEC/HPG to use multiple parallel models, OpenMP, OpenMP with Target Offload, and OpenACC, the submitted candidate need only to use MPI and at least one of the models. If only using OpenMP, there should be nothing in the code that would prevent it from being offloaded to accelerator devices. We encourage you to review the search program, and even if you are not quite sure that your application fits, submit your code as a candidate! Internal Timer TableWhen starting to look at weak scaling, we determined that only the core computation time should be used to compute the FOM. If we included the overhead time, users would need to increase the number of time steps or workload size higher than necessary in order to amortize the overhead. As such, we added internal timers, using MPI_Wtime, to break out the MPI start-up overhead, the application initialization time, and the core compute time (core compute includes MPI communication time). We thought it useful enough that we decided to include this in the SPEChpc v1.1 benchmark, with the internal times shown in the log files. Optionally, you can have these times added to your reports by setting "showtimer=1" in your config file or setting "runhpc –showtimer=1" when running the benchmark. Don’t worry if you forgot to do either. You can go back and edit the resulting "raw" file (.rsf), setting the “showtimer” field to 1 and reformatting your results with the "rawformat" utility. Full details of this new feature can be found at: https://www.spec.org/hpc2021/Docs/changes-in-v1.1.html#timer. This feature is intended to be used for informational purposes only. It cannot be used in place of the reported SPEChpc benchmark metrics, though it may be useful for scaling studies where the overhead cost can be extracted out. It is also useful for understanding the MPI start-up costs on systems. For example, one user was comparing her system performance to that of a sister organization that had a near identical system but performed much better than hers. She was able to determine that a poor configuration in the nodes start-up was to blame. After fixing this, she was able to save users of her system countless hours of unneeded overhead time. Please give the SPEChpc benchmark a try today and submit your application as a Weak Scale benchmark candidate. Even better, consider having your organization join SPEC/HPG and be part of this exciting new development effort! Home - Contact - Site Map - Privacy - About SPEC 


webmaster@spec.org 
Last updated: Thu Jul 14 16:22:06 EDT 2022 Copyright 1995 - 2026 Standard Performance Evaluation Corporation URL: http://www.spec.org/blog/2022/07/spechpc2021v11.html |
