SPECvirt ® Datacenter 2021 Design Document
1.0 Introduction
The SPECvirt ® Datacenter 2021 benchmark is the next generation of virtualization benchmarking for measuring performance of a scaled-out datacenter. The SPECvirt Datacenter 2021 benchmark is a multi-host benchmark using simulated and real-life workloads to measure the overall efficiency of virtualization solutions and their management environments.
The SPECvirt Datacenter 2021 benchmark differs from the SPEC VIRT_SC ® 2013 benchmark in that SPEC VIRT_SC benchmark measures single host performance and provides interesting host-level information. However, most of today’s datacenters use clusters for reliability, availability, serviceability, and security. Adding virtualization to a clustered solution enhances server optimization, flexibility, and application availability while reducing costs through server and datacenter consolidation.
The benchmark provides a methodical way to measure scalability and is designed to be utilized across multiple vendor platforms. The primary goal of the benchmark is to be a standard method for measuring a virtualization platform’s ability to model a dynamic datacenter virtual environment. It models typical, modern-day usage of virtualized infrastructure, such as virtual machine (VM) resource provisioning, cross-node load balancing including management operations such as VM migrations, and VM power on/off. Its multi-host environment exercises datacenter operations under load. It dynamically provisions new workload tiles by either using a VM template or powering on existing VMs. As load reaches maximum capacity of the cluster, hosts are added to the cluster to measure scheduler efficiency.
Rather than offering a single workload that attempts to approximate the breadth of consolidated virtualized server characteristics, the benchmark uses a five-workload benchmark design:
OLTP database workload (HammerDB)
Hadoop / Big Data environment (BigBench)
AllInOneBench mail server emulating the resource profile of SPEC VIRT_SC 2013’s SPECimap
AllInOneBench web server modeled after the workload profile of SPEC VIRT_SC 2013’s modified SPECweb ® 2005 benchmark
AllInOneBench collaboration server emulating a resource profile based on customer data for collaboration services
See VMs and tiles for details.
All workloads drive pre-defined, dynamic loads against sets of virtualized machines. The workloads use:
Another of benchmark’s goals is ease of benchmarking. Manually creating the VM, installing the operating system into it, adjusting specific OS tuning settings, installing workload applications, and generating the workload data can be complicated and prone to error. To address this, SPEC provides a pre-built appliance containing the controller, workload driver clients, and workload VMs for the base metric. The software is pre-loaded and pre-configured in an effort to minimize the benchmarker’s intervention and reduce implementation time and effort.
The required VM appliance provides results for the base measurement and eliminates any performance variation of the OS and software stack. This ensures the focus is on performance of the total virtualization solution. It is distributed as an OVF package, making it quick to install through VM import and requiring no configuration beyond setting system resources (for example, vCPUs and memory).
As with all SPEC benchmarks, an extensive set of run rules govern benchmark disclosures to ensure fairness of results. Results are not intended for use in sizing or capacity planning. This benchmark does not address application virtualization.
2.0 Overview
2.1 Component workloads
The benchmark suite consists of several workloads that represent applications commonly deployed in virtualized datacenter environments. For the departmental workloads, the resource requirements (CPU, memory, disk I/O, and network utilization) that the individual workloads consume are modeled on observed host servers for the given workloads and reasonable user activity and working set data levels. The AllInOneBench driver is used for these workloads in place of production software stacks to simplify the benchmark implementation and usability. The component workloads are:
Mailserver - This workload represents a IMAP server.
Webserver - This workload represents an HTTP web server which communicates with a client emulator external to the SUT using HTTP transactions.
Collaboration servers - This workload represents a server handling collaborative activities of a company web conferencing and/or file-sharing server.
HammerDB - This workload represents an online transaction processing environment and includes both an application tier VM issuing ODBC requests to an ACID compliant database (DBMS) VM.
BigBench - This workload represents a BigData/Hadoop environment structured around a product retailer with physical and online stores.
Members of the SPEC Virtualization committee researched datacenter workloads, determined suitable load parameters, and refined the test methodology to ensure that results scale with the capabilities of the system and that throughput results for each workload are consistent across technologies barring resource bottlenecks. The benchmark requires significant amounts of host memory (RAM), storage, and networking capability in addition to processors on the SUT. Client systems used for load generation must also be adequately configured to prevent overload. Storage requirements and I/O rates for disk and networks are non-trivial. The benchmark does not require that each workload have a maximum number of logical (hardware-wise) processors and is designed to run on a broad range of host systems.
This mix features light, medium, and heavy workloads. The individual workload scores are weighted accordingly to prevent undue influence of any one workload on the primary metric.
See Workload details for more information regarding the individual workloads.
2.2 VMs and tiles
The benchmark presents an overall workload that achieves the maximum performance of the platform when running one or more sets of Virtual Machines called “tiles” while meeting Quality of Service criteria.
2.2.1 Tile composition
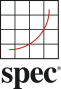
The benchmark’s unit of work is referred to as a tile. A tile contains a set of workloads as illustrated below.
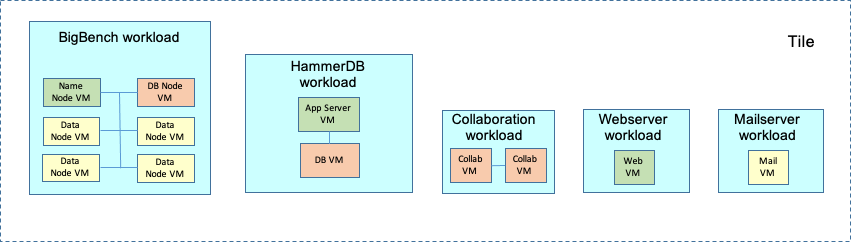
To emulate typical datacenter network use, all VMs use a network to communicate to and from the clients and controller in the testbed. Any communication outside the SUT must be over a separate physical network.
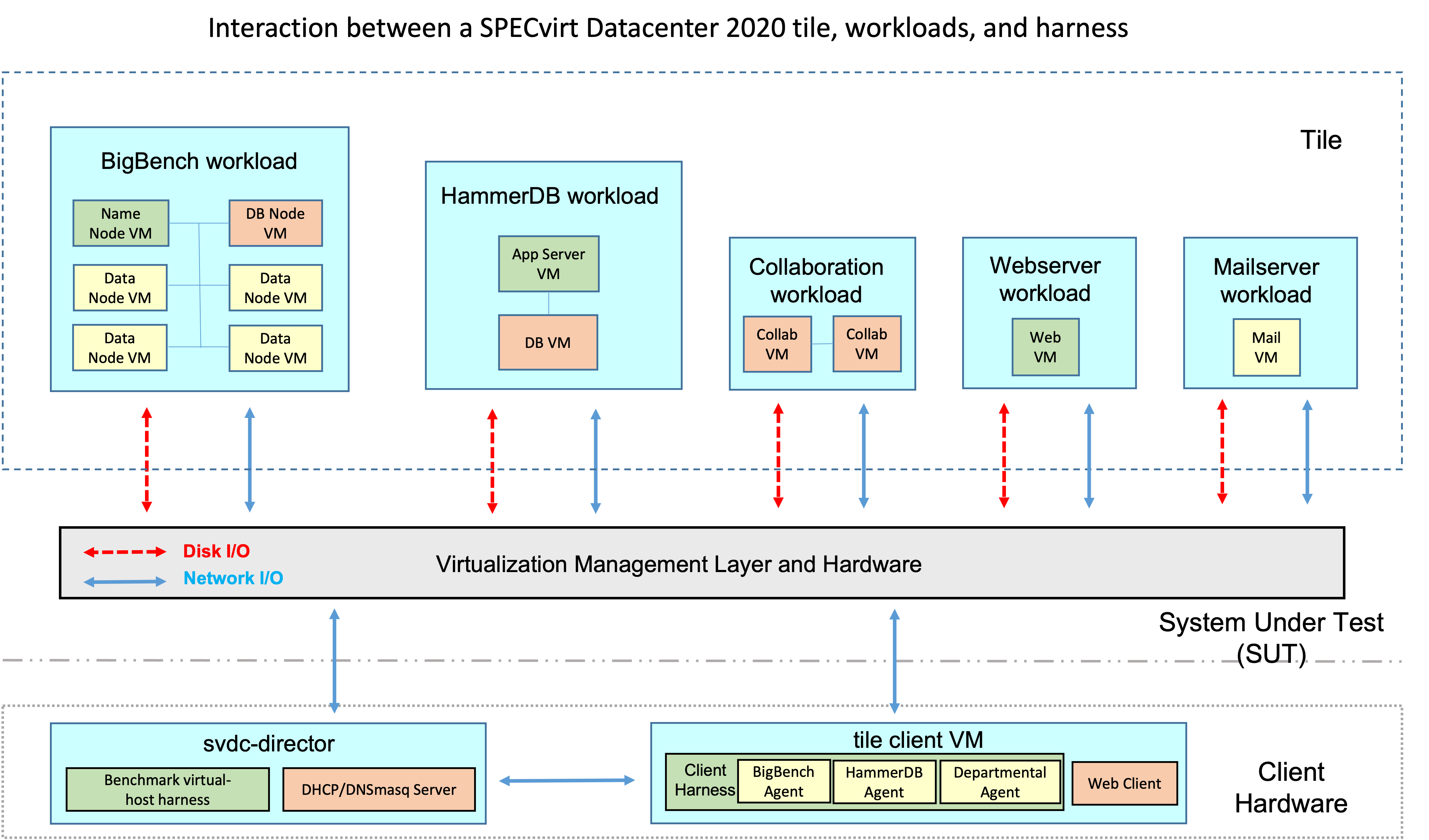
2.2.2 Multiple tiles
Scaling the workload consists of running an increasing number of tiles. Peak performance is the point at which the addition of another tile (or fraction of a tile) either fails the Quality of Service (QoS) criteria in any tile or fails to improve the overall metric.
2.2.3 Fractional tiles
When the SUT does not have sufficient system resources to support the full load of an additional tile, the benchmark offers the use of a fractional load tile. A fractional tile consists of a subset of the workloads.
Specifically, the harness adds full workloads in the following order in terms of load.
Mail
Web
Collaboration
HammerDB
You can use a fractional tile during both phase1 and phase3 by adding “.<FractionalTile>” to the number of Tiles specified for numTilesPhase1 and numTilesPhase3 in Control.config.
The accepted options for <FractionalTiles> are:
“.2” = Mailserver
“.4” = Mailserver + Webserver
“.6” = Mailserver + Webserver + Collaboration Servers
“.8” = Mailserver + Webserver + Collaboration Servers + HammerDB
2.3 Measurement phases
The measurement interval consists of three phases:
Phase 1, Initial Load Phase: This phase measures the throughput capacity of the SUT as load (tiles, including partial tiles) is added to the initial set of hosts.
Phase 2, Host Provisioning Phase: During this phase, the harness activates an additional host in the datacenter for every three online hosts. The ‘offline hosts’ are brought online allowing the hypervisor scheduler to place and migrate VMs to the newly available host.
Phase 3, Final Load Phase: During this phase, additional tiles (including partial tiles) are added to reach the datacenter’s maximum sustainable load-level while still meeting all QoS requirements.
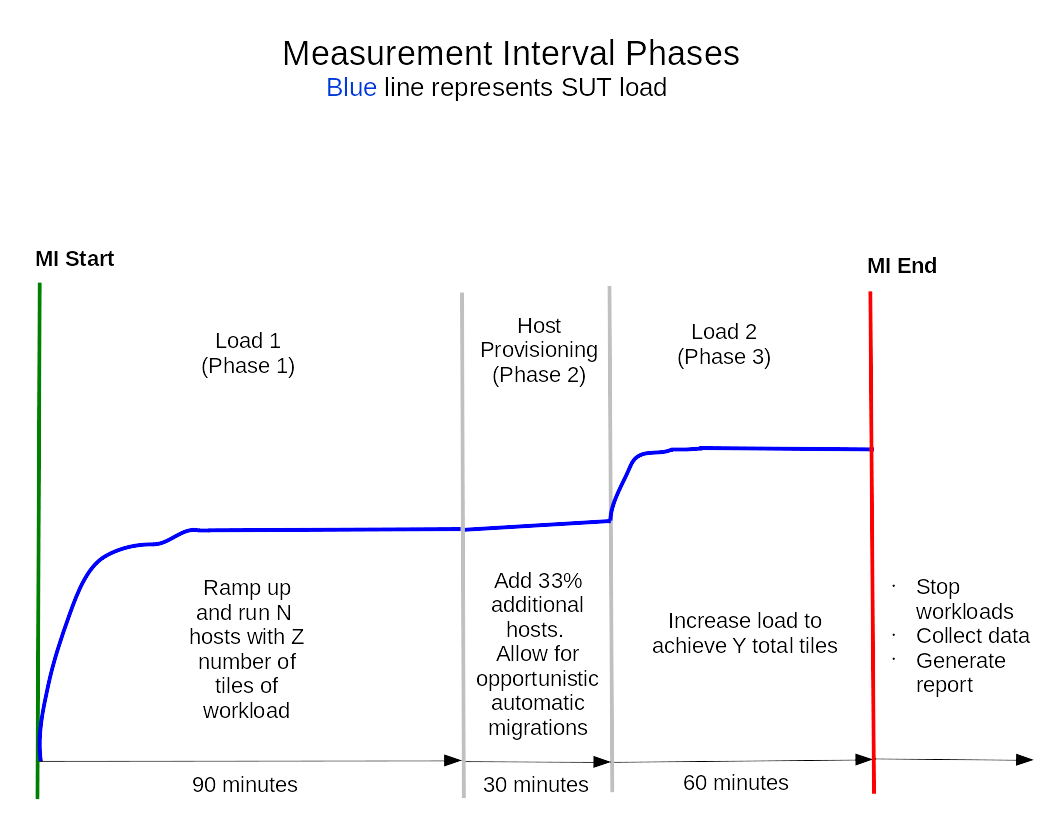
The metric is the sum of the normalized throughput score of all tiles. See Primary metric for details.
2.3.1 Workload throughputs
The benchmark measures datacenter performance using multiple workload models. BigBench utilizes a speed model, which measures how fast a datacenter can complete individual tasks. The other workloads (Mailserver, Webserver, Collaboration server, and HammerDB) utilize a throughput model, which measures how many tasks a datacenter can accomplish in a certain amount of time.
The overall score is based upon the following metrics of the component workloads for each tile over the three-hour Measurement Interval:
Mailserver - the sum of all operations completed
Webserver - HTTP requests completed
Collaboration server - operations completed
HammerDB - Number of completed New Order transactions
BigBench - Number of total completed queries, not to exceed 66. (Maximum of six cycles of the predefined 11 query set)
2.4 Primary metric
The score for each tile is a supermetric that is the weighted geometric mean of the normalized submetrics for each workload.
The metric is output in the format SPECvirt ® Datacenter-2021 <Score per Host> per host @ <# hosts> hosts. For example:
SPECvirt ® Datacenter-2021 = 4.046 per host @ 4 hosts
The overall metric is the sum of all the tiles’ scores divided by the number of hosts in the SUT.
Where:
Tile score = [mail^(0.11667)] * [web^(0.11667)] * [collab^(0.11667)] * [HammerDB^(0.30)] * [BigBench^(0.35)]
Overall Score = (tile score1) + (tile score2) + … (tile scoreN)
Score per Host = Overall Score / $numHosts
The submetrics must meet the QoS criteria defined for each workload as well as any other validation that the workload requires. The details of the QoS criteria are documented in the SPECvirt Datacenter 2021 Run and Reporting Rules.
2.5 Measurement Interval (MI) and phases
The Measurement Interval (MI) consists of three separate timed phases. These phases occur sequentially. The MI begins at the start of Phase 1 and ends when Phase 3 completes.
Initial Load (Phase 1)
Duration: 90 minutes
During this phase, three-fourths of the hosts are available for provisioning and workload activity.
The beginning of Phase 1 represents the beginning of the MI.
The harness initiates the tile workloads, deploying and/or powering on any required VMs as necessary. The tiles may be started in rapid succession or in delayed sequences (specified as in the Control.config) and may be incrementally extended using the “delay factors”. All tiles and workloads start and report to the harness before the end of this phase.
Host Provisioning (Phase 2)
Duration: 30 minutes
This phase activate offline host(s) that were not available during Phase 1. No new workloads are added during this phase. The goal behind this phase is to give the virtualization solution the opportunity to re-balance the VMs for better performance using the newly added host(s).
Final Load (Phase 3)
Duration: 60 minutes
The harness deploys additional workloads (tiles) to take advantage of the SUT with the host(s) which exited maintenance mode from Phase 2. As in Phase 1 the tiles are started at the rate determined by the workload delay settings (including any additional delay factors) specified in Control.config. These workloads are added in order starting from the last workload deployed in phase 1.
The end of Phase 3 represents the end of the MI.
3.0 Testbed preparation
- To prepare the environment for initial benchmark tests, the user must first:
configure the SUT environment (hosts, network, storage, management server, etc)
deploy the svdc-director VM to a host external to the SUT
execute required deployment scripts (prepSUT.sh, DeployClients.sh, etc) to deploy SUT and client VMs for all tiles
See the SPECvirt Datacenter 2021 User Guide for details.
4.0 Benchmark workflow
The following illustrates the benchmark workflow:
Execute the script “runspecvirt.sh $testname [ CLI | GUI ] ” to initiate the test. This then performs the following:
Invokes prepTestRun.sh which executes the following actions:
Build the measurement profile from the configuration specified in Control.config.
Restores the database for HammerDB VMs.
Ensure the workloads on the SUT VMs are in the proper initial state for the test measurement.
Power off all SUT VMs.
Place all offline hosts in maintenance mode.
Reboot client VMs and ensures required services are initialized on startup.
Start CloudPerf prime services.
Invokes user-defined $initScript which allows any user-defined scripts (such as performance monitoring tools to be started on the SUT hosts, clients, etc.)
Calls CloudPerf CLI, passing the measurement parameters to the CloudPerf harness. (Optionally, Liveview monitoring GUI is displayed.)
CloudPerf then starts the measurement using the events listed in run.xml to execute the benchmark workflow as per below:
<Start of Measurement Interval>
<phase 1>
For the departmental workloads (Mailserver, Webserver, and Collaboration servers) this entails:
For HammerDB and BigBench VMs (which are pre-configured) this entails:
<phase 2>
<phase 3>
<End of Measurement Interval>
Send stop signal to departmental and BigBench workloads (Note, HammerDB is preconfigured at deploy time to stop at the appropriate time.)
Execute endRun.sh which executes the following:
collect_log.sh (collect all workload logs)
“sutConfig.sh 1” (collects end-of-measurement SUT configuration)
RawFileGenerator.sh (generates .raw file and creates FDR report)
getSupport.sh (generates the supporting tarball)
Invoke exitScript.sh (user-defined content) e.g., terminate any performance monitoring statistics tools, as needed.
Global stop signal sent to terminate CloudPerf workload agents
5.0 Workload details
The five primary workloads used in this benchmark are modified versions of HammerDB and BigBench as well as a simulated mail server, web server, and collaboration server. Their resource utilizations are:
Workload |
CPU |
Memory
bandwidth |
Network
(Mb/sec) |
I/O
(MB/sec) |
|---|
mail |
moderate |
low |
low |
high |
web |
moderate |
moderate |
high |
low |
collaboration |
moderate |
moderate |
high |
moderate |
HammerDB |
high |
high |
low |
high |
BigBench |
highest |
moderate |
moderate |
high |
5.1 Mail server workload
This workload represents a departmental IMAP mail server. This synthetic workload utilizes the AllInOneBench tool to closely model the SPEC VIRT_SC 2013 mail workload’s resource utilizations and characteristics. The primary characteristics of this workload include fairly heavy disk I/O usage and moderate stressing of the network stack. The working set size (representing the mailserver storage requirements for a departmental mail server) is ~11GB.
The mailserver VMs are deployed during the Measurement Interval. During initial power-on, the workload dynamically generates the 11GB fileset prior to the workload execution, resulting in an additional disk I/O write component to the initialization of this VM.
The disk IO for the workload is a 50/50 mix of random and sequential operations. The read/write mix is 40/60.
To ensure the TCP/IP stack is exercised, there is a network component to the mailserver workload. However for ease-of-benchmarking there is no external mail client issueing and receiving requests. The network requests do still occur but are made to and from the loopback device.
For details on the specifics of the mailserver workload transaction and and fixed settings that define the CPU, memory, network, and disk subtransactions, see Appendix A.
5.2 Web server workload
This workload includes an external client with multiple unique end-users issuing HTTP requests to the SUT webserver VM. This synthetic workload utilizes the AllInOneBench tool to closely model the resource utilizations of the SPEC VIRT_SC 2013 benchmark’s modified SPECweb2005 workload.
The primary characteristics of this workload are heavy network communications between the client and the SUT (north-south) and moderate CPU and memory usage. The working set is a mix of text and binary files with a total working set of ~17GB. There are 60,000 text files, and 60,000 binary files with an average size of 100K each. The web client (which resides on the client VM for the given tile) requests a set of files from a uniform random distribution across the available 120,000 text and binary files. The webserver VM simultaneously performs a predefined number of CPU, memory, and disk operations to emulate the backend processing of typical webservers. The resulting combination of the client requests and additional processing comprise a “webserver transaction” for throughput calculations.
The webserver VMs are deployed during the Measurement Interval. During initial power-on, the workload dynamically generates the 17GB fileset prior to the workload execution, resulting in fairly heavy disk I/O write component to the initialization of this VM.
For details on the specifics of the webserver workload transaction and and fixed settings that define the CPU, memory, network, and disk subtransactions, see Appendix A.
5.3 Collaboration server workload
This workload represents intra-business (east-west) communications between two VMs within a tile. It emulates collaborative activities such as meeting software, file sharing, and presentations. This includes the heavy bi-directional and streaming network activities common in these environments and moderate CPU and memory usage. The AllInOneBench tool controls the operations for this workload.
The primary characteristics of this workload are bi-directional network throughput as well as moderate disk read/write activity. The working set size for each collaboration server is 9GB.
The collaboration server VMs are deployed during the Measurement Interval. During initial power-on, the workload dynamically generates the 9GB fileset on each collaboration server prior to the workload execution.
For details on the specifics of the collaboration workload transaction and and fixed settings that define the CPU, memory, network, and disk subtransactions, see Appendix A.
5.4 HammerDB workload
The HammerDB workload is a modified version of the popular HammerDB OLTP database stress benchmark. This workload primarily exercises a MYSQL database instance. The SQL commands are issued from a separate application server and sent to the MySQL database using ODBC.
Modifications to the think-time and keying-time were made to the standard HammerDB implementation to create a fixed workload injection rate at a significantly lower total Warehouse Count. This allows for configuring a DBMS VM with reasonably modest vCPU requirements while also greatly reducing the total database size compared to more traditional HammerDB configurations where the end-goal is to evenly stress the entire server and I/O subsystem with a single instance of HammerDB.
Response Time Requirements
A check is performed by the RawFileGenerator tool which check HammerDBs results to verify NewOrder TPS (NOTPS) are greater than 200 for each tile. Lower than 200 NOTPS results in a QoS failure for that tile.
5.5 BigBench workload
BigBench is a Big Data solution that uses the data of a store and web sales distribution channel augmented with semi-structured and unstructured data. To measure the performance of Hadoop-based Big Data systems, BigBench executes a set of frequently performed analytical queries in the context of retailers with physical and online store presence. The queries are expressed in SQL for structured data and in machine learning algorithms for semi-structured and unstructured data. The SQL queries use Hive, while the machine learning algorithms use machine learning libraries, user defined functions, and procedural programs.
For this benchmark, the query set is a subset of the original benchmark query set. This query subset allows for multiple instances to complete short-and medium-running query sets within a reasonable time for the benchmark.
5.5.1 Modified query list
BigBench uses a subset of the available queries and executes them in the following order:
1,3,6,7,8,12,13,16,19,20,29
The harness validation tools verify that each set of the above 11 queries completes in 4500 seconds. The set of 11 queries above repeats for a maximum of six iterations, after which point the BigBench VMs are idle.
Unfinished individual queries gets no credit; only successfully finished queries get credit.
6.0 System Under Test (SUT) environment
A cluster is a group of hosts that together act like a single system and provides availability, failover, reliability, and balance across workloads. The benchmark defines the cluster as all hosts that contain the workload VMs.
The System Under Test (SUT) contains the cluster and the hypervisor management server. The management server provides a centralized platform for managing the virtualization environment. It is a key component of any datacenter and for the benchmark is considered part of the SUT.
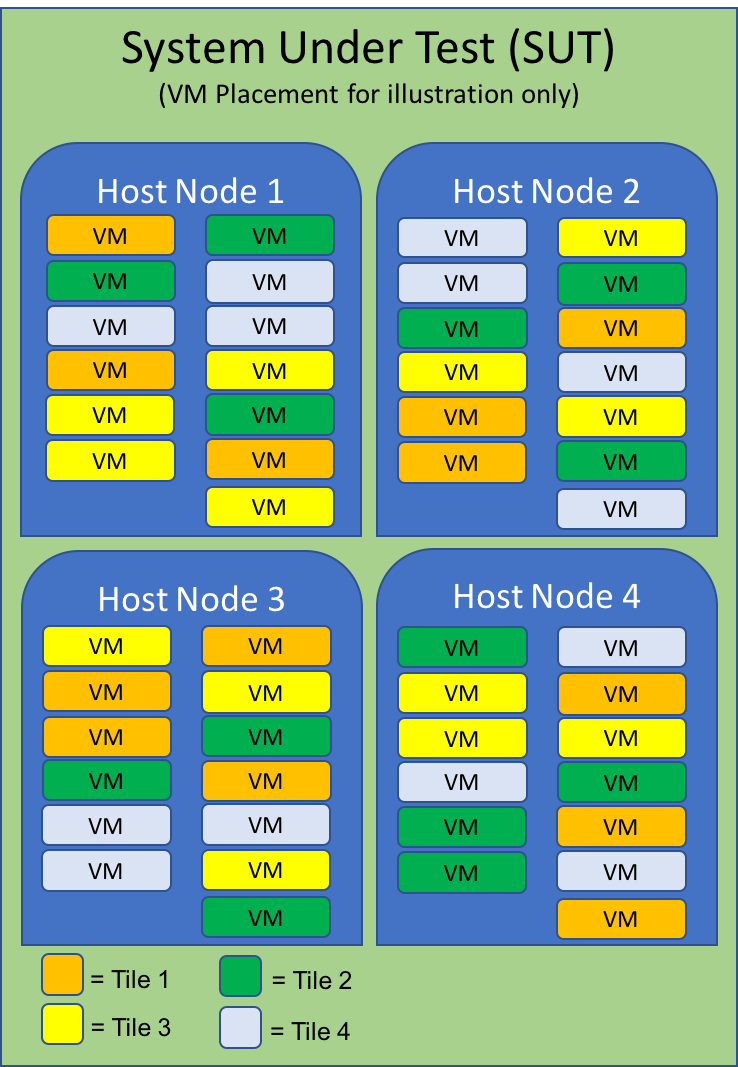
For the benchmark, the total numbers of hosts in the cluster must be a multiple of four. Using four hosts creates a reasonably-sized pool from which resources can be added or removed and lets the benchmark exploit the load balancing features of virtualization solutions. It also aligns with the typical chassis configurations for datacenter solutions from a hardware perspective. For example, typical configurations for datacenters include many four-node 2U clusters as well as blades often in multiples of four.
The cluster hosts must be homogeneous. That is, each host in the cluster is identical in its system configuration (number and type of CPUs, speed and quantity of memory, network controllers, and storage controllers).

A hypervisor management server VM or physical server can run on an separate host that does not need to be homogeneous with the SUT host nodes running the workload VMs. For example, a non-x86-based hypervisor might use an external x86-based management server or management server appliance.
All management server and cluster storage is considered part of the SUT. All network components used to provide intra-SUT communications (bridges, switches, NICs, and so on) are also part of the SUT.
Note if the management server resides on a host that also contains client VMs, that host’s hardware is then considered part of the SUT.
7.0 Workload controller
7.1 Benchmark harness
The VM OS and application software utilize open source and OS distribution components which are included and supplied in an OVF appliance with the benchmark kit. The appliance contains an open source operating system (CentOS distribution), software, harness, and workload VM software. The appliance is “locked-down” and does not allow any changes to it including OS tuning and application version upgrades.
The major components of the benchmark kit are contained in the following locations:
/root contains initialization scripts including “makeme_svdc-director.sh” and other automation scripts that are invoked at boot time for deployed VMs
$CP_HOME/bin contains Control.config and scripts required to configure, initialize, and start the benchmark & LiveView GUI, and manually invoke the report generator
$CP_COMMON contains the scripts that initially deploy, power on, delete, etc the SUT VMs and clients
/root/AllInOneBench contains the AllInOne Benchmark which executes the departmental VM workloads
/opt/HammerDB contains HammerDB setup scripts and benchmark implementation
/opt/Big-Bench contains the BigBench benchmark harness
/opt/createApacheCluster contains the Apache Hadoop software,and associated components the Hadoop environment (hive, mahout, zookeeper) requires
7.2 CloudPerf harness design
The datacenter deployment scripts configure the VM hardware (namely the MAC address). The dnsmasq server uses the MAC address to provide the hostname at VM initialization. This hostname identifies the proper workload type and is used at initial boot to configure the OS tuning parameters, application stack, and initialized datasets. In this way, the VM requires no interaction from the benchmarker.
The harness utilizes a general purpose, highly scalable test framework called CloudPerf. CloudPerf provides the high level framework for the test environment. It is responsible for managing Measurement Interval activities such as VM deployments, workload start/stop signals, throughput polling, aggregation of measurement data during the measurement, and post-measurement processing and test report generation.
CloudPerf is a protocol-independent performance test tool. It allows distributed test setups with both load generators as well as test systems spanning multiple nodes. Its capabilities allow dynamically changing load or injecting events into the system to trigger actions through preconfigured measurement configuration files. A polling framework provides throughput data from the agents the LiveView GUI monitors during the measurement and can be used for real-time analysis or troubleshooting.
The harness uses two of the CloudPerf functional object types: agents and services. The agents provide the interface between the harness and the underlying workloads themselves including performance statistics collection. The services provide the hypervisor control operations to the datacenter environment.
7.3 CloudPerf and workload polling
During the Measurement Interval, the three workload agents polls for each tile for updated statistics every 10 seconds. CloudPerf receives these updates and displays the aggregate throughput across all tiles for each workload type in LiveView, if active. The workload polling data includes throughput and response time information. The polling data itself is not used to calculate the final scores but provides real-time updates to the benchmarker.
7.3.1 Throughput and events (LiveView GUI)
LiveView allows for general viewing of the measurement progress, status, and event triggers.
LiveView is the GUI that displays the events (VM deployments, VM Power On, workload start, etc) as they occur on a dynamic graph. The graph also displays a dynamic histogram for each workload, where each workload is represented as a separate color. For departmental workloads and HammerDB, the throughput displayed represents the aggregate throughput for that workload over any active tiles. For BigBench, the graph displays a ‘spike’ whenever a query completes for any tile, where taller spikes indicate a query completed on multiple tiles during the associated 10 second polling interval.
You can analyze the throughput or event tags for any chosen interval length within a measurement. To select an interval, left-click and hold to draw a box around the region to zoom in. You can repeat this multiple times until you reach the maximum zoom. To zoom out, click the “-” (minus icon) at the bottom the graph. Clicking the “+” (plus icon) zooms in on the current active portion of the measurement.
7.3.2 Polling and run time result reporting
CloudPerf polls the workload agents, which in turn poll their respective SUT VM workloads every 10 seconds. Note: CloudPerf does not rely on these polling results for determining final scores. The harness tools use the throughput summaries reported at the end of the MI in the workload agent logs to calculate the benchmark metrics.
The workload agent records the polling that is returned and visible to LiveView in the workload agent logs on each client. The harness then copies to the results directory on the svdc-director VM at the end of the measurement. Additionally, you can monitor the workload agent’s logs and see transaction results during the measurement via the script $CP_HOME/bin/client-log-summary.sh.
See SPECvirt Datacenter 2021 Run and Reporting Rules, clause 4.4.1.1 Departmental Workloads for the required per-tile QoS thresholds for each workload.
For the departmental workloads (mail, web, collab), polling is recorded at 10 seconds intervals in $CP_HOME/logs/cp-agent-svdc-t<tilenum>-client-1.log. e.g.:
29.06.2020 16:21:09 INFO [Thread-11] svdc-t001-mail mail: Txns/sec= 58
29.06.2020 16:21:09 INFO [Thread-11] svdc-t001-mail mail: Avg RT= 161
29.06.2020 16:26:39 INFO [Thread-14] svdc-t001-web webSUT: Txns/sec= 95
29.06.2020 16:26:39 INFO [Thread-14] svdc-t001-web webSUT: Avg RT= 95
29.06.2020 16:26:44 INFO [Thread-20] svdc-t001-collab1 collab: Txns/sec= 40
29.06.2020 16:26:44 INFO [Thread-20] svdc-t001-collab1 collab: Avg RT= 244
29.06.2020 16:26:45 INFO [Thread-23] svdc-t001-collab2 collab: Txns/sec= 46
29.06.2020 16:26:45 INFO [Thread-23] svdc-t001-collab2 collab: Avg RT= 216
For the HammerDB workload, the NewOrderTPS (NOTPS) throughput polling is recorded every 10 seconds in $CP_HOME/logs/cp-agent-svdc-t<tilenum>-client-1.log
Note, the average Response Time per transaction is not recorded in the polling for HammerDB, e.g.:
29.06.2020 16:21:56 INFO [Thread-7] HammerDB: NewOrderTPS= 273.30
For the BigBench workload, polling is reported as queries complete in $CP_HOME/logs/cp-agent-svdc-t<tilenum>-client-2.log. The polling reports the completed query along with its duration.
Note, there is only one active query (i.e., one stream) at at time for each tile, e.g.:
29.06.2020 16:28:47 INFO [Thread-7] BigBench: COMPLETED QUERY 3. Query Response Time = 193 seconds.
8.0 CloudPerf and workload agent interaction
The benchmark test harness utilizes a control framework called CloudPerf. CloudPerf is designed to accommodate controlling signals to - and monitoring responses from - large scale-out environments with capabilities to control a variety of applications and services. At the top level, CloudPerf has a single primary controller that takes a set of XML files as input defining:
This design overview discusses the implementation using CloudPerf as the control harness as it relates to the benchmark. For a more in-depth understanding of CloudPerf, from the svdc-director VM GUI, invoke:
firefox $CP_COMMON/docs/index.html
There are three CloudPerf XML input files specific to the benchmark:
workload.xml
deployment.xml
run.xml
The top-level benchmark script runspecvirt.sh invokes the genConfig.sh script that generates these files automatically at run time. The genConfig.sh script uses the defined values in Control.config to generate the XML configuration files. The svdc-director VM sends workload agent related commands to each client’s prime agent based on the topology defined in these XML files. The local prime agent sends the workload command to the appropriate local workload agent, which then initiates the workload specific task.

8.1 workload.xml
The three top-level workload drivers used in the benchmark are controlled by a workload agent, which is itself controlled by the local client’s prime agent. The workload agents are defined in $CP_HOME/config/workloads/specvirt/workload.xml in the format:
<driver name="AllInOneAgent_T001" type="external">
<workload>
<class-name>org.spec.allinone.AllInOne</class-name>
<statistics-provider>
<sampling-interval>1</sampling-interval>
</statistics-provider>
</workload>
</driver>
<driver name="HammerDBAgent_T001" type="external">
<workload>
<class-name>org.spec.virtdc.agent.HammerDBLoadGen</class-name>
<statistics-provider>
<sampling-interval>1</sampling-interval>
</statistics-provider>
</workload>
</driver>
<driver name="BigBenchAgent_T001" type="external">
<workload>
<class-name>org.spec.virtdc.BigBenchLoadGen</class-name>
<statistics-provider>
<sampling-interval>1</sampling-interval>
</statistics-provider>
</workload>
</driver>
(Example for tile 1)
The functionality of these agents include:
AllInOneAgent: starts, polls, and stops the departmental workloads (mail, web, collaboration). Note that this agent is unique in that the AllInOneBench application is more tightly integrated with CloudPerf, as the agent interface has been incorporated into the workload’s control functions. The other two workload agents start and stop their respective benchmarks via scripts, whereas AllInOneAgent is capable of more direct functionality (including polling) between CloudPerf and the AllInOneBench application.
HammerDBAgent: starts, polls, and stops the HammerDB workload. The HammerDBAgent starts the HammerDB workload via the script “/opt/HammerDB/spawnHammerDB.sh”. Since the VMs have been powered on moments before this script is called, additional script logic ensures the application and database servers are available and ready to process the workload. The polling returns the output from a query which determines the number of NewOrder transactions completed in the past ten seconds (recorded to /opt/HammerDB/pollingstats.out on each client).
BigBenchAgent: starts, polls, and stops the BigBench workload. The BigBenchAgent starts the BigBench workload via the script “/opt/Big-Bench/bin/svdc-bb-run.sh”. The script contains logic to ensure the VMs and services are running and ready to begin the BigBench workload prior to issuing the start command. The polling monitors the contents of /opt/Big-Bench/BigBenchResult.log on each client and reports query completion details.
8.2 deployment.xml
The XML definition for the above three agents reside in $CP_HOME/config/workloads/specvirt/deployment.xml. E.g., for the first tile, the three workload agents are given a unique name, and are assigned to svdc-t001-client:
<hosts names="svdc-t001-client">
<driver name="BigBenchAgent_T001" type="external"/>
<driver name="HammerDBAgent_T001" type="external"/>
<driver name="AllInOneAgent_T001" type="external"/>
</hosts>
The deployment.xml also contains an entry for “HV Service” which is the method defined that allows CloudPerf to execute the management server operations. This functionalitry is specific to the svdc-director VM only and defined in the following lines in deployment.xml:
<dependencies>
<depends file="HV" type="service"/>
</dependencies>
<deployment>
<group name="ALL" desc="All Systems" report-poll-qos="true">
<hosts names="svdc-director">
<service name="HV"/>
</hosts>
...
8.3 run.xml
Definitions and event signal pacing are specified in run.xml. This file determines the timing for harness signals sent during the Measurement Interval (MI) and is located in $CP_HOME/config/workloads/specvirt/run.xml. The file contains:
Invocation of startRun.sh, which collects and creates required pre-test measurement information
Workload deployment and start signals for each tile
Signals to bring the “offline hosts” online for Phase 2
Workload stop signals
Invocation of endRun.sh
The optional userExit.sh script
Global CloudPerf stop signal
For an example run.xml for a one-tile measurement, see Appendix B.
NOTE: For a compliant measurement, the above three xml files must never be edited. The harness automatically generates these at run time.
8.4 Invocation of hypervisor management operations
The HV Service described above in deployment.xml resides on the svdc-director VM. This interface handles the management operations which initiate events via API calls on the management server. These operations occur during the MI and include:
Script Name |
Input Parameters |
Comments |
|---|
startRun.sh |
[none] |
Used to collect initial necessary
hypervisor environment data for
benchmark results. |
DeployVM-AIO.sh |
<VM name>
<MAC address> |
Deploys indicated departmental
workload VM with indicated MAC |
PowerOnVM.sh |
<VM name> |
Powers on indicated VM |
ExitMaintenanceMode.sh |
<hostname> |
Brings indicated host out of
maintenance mode |
endRun.sh |
[none] |
Collects workload agent logs and
final hypervisor environment
data. Calculates and reports
benchmark results |
userExit.sh |
[none] |
Sample user script to perform
post-benchmark monitoring
tasks such as collecting output of
performance monitoring scripts |
8.5 SUT networking
For ease of implementation and use, the VM deploy scripts and the dnsmasq service resides on the svdc-director VM and sends all VM network configuration information via harness parameters.
The benchmark uses DHCP and DNS protocols to provide a mechanism so that the benchmarker does not have to configure the VM. Since DHCP is a broadcast protocol, it is recommended for the SUT network to be physically isolated from networks that host other DHCP servers (for example, campus, lab, or local network). However, dnsmasq is configured to eliminate responding to requests that originate from outside the testbed environment.
The OS on the template VM has no defined network or hostname. The deployment scripts on svdc-director VM configure the NIC (eth0) on the target VM with a unique MAC address based on the workload type and tile number. At boot time, the corresponding VM requests a DHCP IP address (the MAC address is included with the request). The dnsmasq service then looks for this MAC entry in the svdc-director VM’s dnsmasq.dhcp-hostsfile and retrieves the associated hostname. dnsmasq then checks /etc/hosts for this hostname and responds to the client with the corresponding IP address.
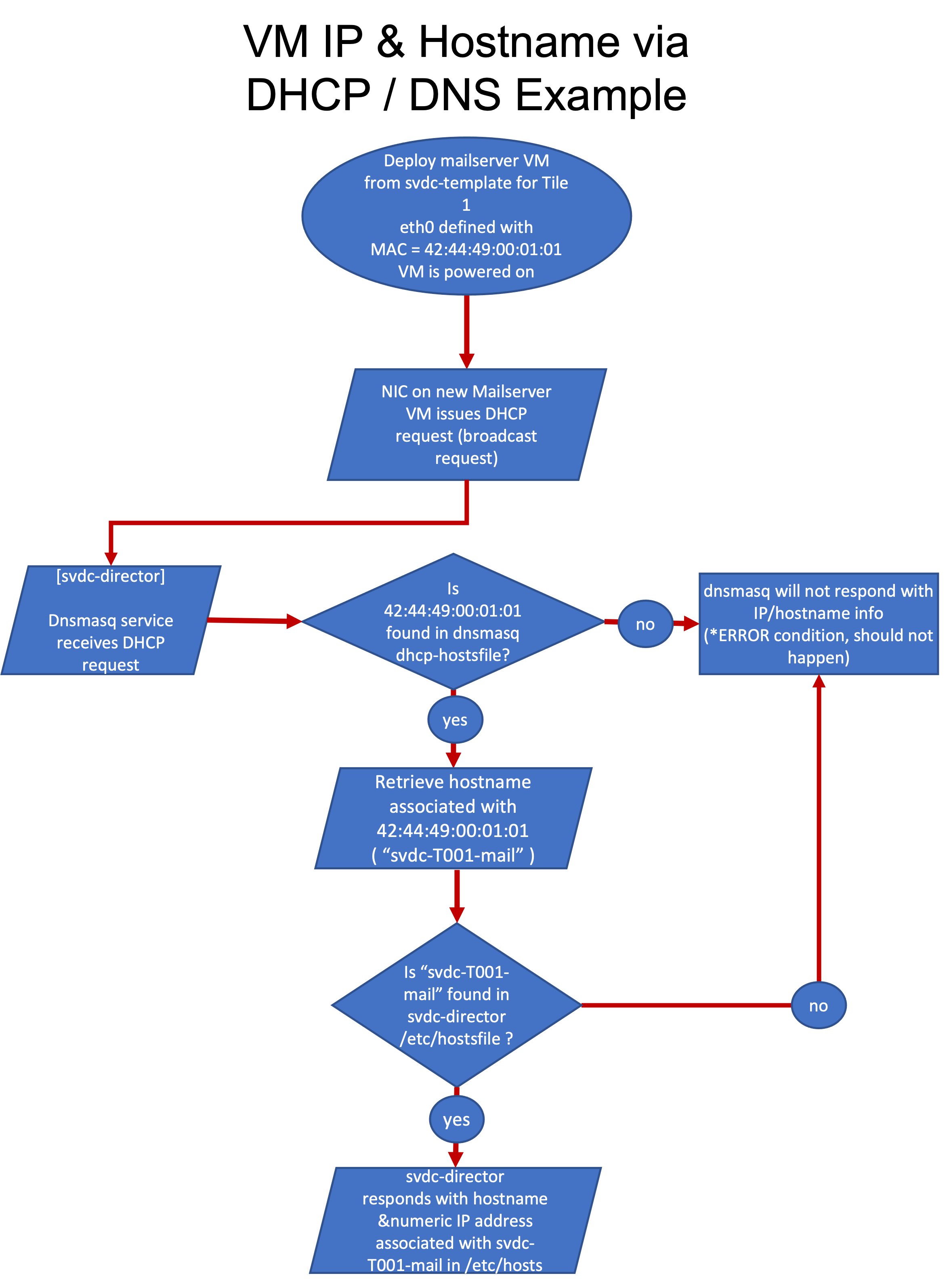
8.5.1 MAC and IP address assignment for VMs
The user may choose the first three octets that all client and SUT VMs use with the variable “MACAddressPrefix” in Control.config. This is set to “42:44:49:” by default.
The fourth and fifth octets are used to set the tile number (up to 254). The last octet is used to define the VM type (based on workload type or client).
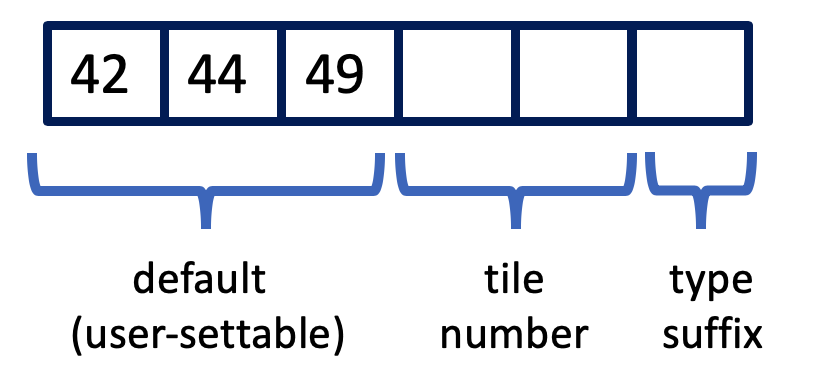
The following table shows the default VM name, IP address assignments, and MAC addresses for tile one:
Tile one
VM name |
VM type |
- Tile one default
IP address
|
- Tile one default
MAC address
|
|---|
svdc-t001-client |
Client |
172.23.1.1 |
42:44:49:00:01:01 |
svdc-t001-mail |
Mailserver |
172.23.1.1 |
42:44:49:00:01:01 |
svdc-t001-web |
Webserver |
172.23.1.2 |
42:44:49:00:01:02 |
svdc-t001-collab1 |
CollabServer |
172.23.1.3 |
42:44:49:00:00:03 |
svdc-t001-collab2 |
CollabServer |
172.23.1.4 |
42:44:49:00:01:04 |
svdc-t001-hdb |
HammerDB
DBserver |
172.23.1.6 |
42:44:49:00:01:06 |
svdc-t001-happ |
HammerDB
Appserver |
172.23.1.7 |
42:44:49:00:01:07 |
svdc-t001-bbnn |
BigBench
(Name Node) |
172.23.1.8 |
42:44:49:00:01:08 |
svdc-t001-bbdn1 |
BigBench
(Data Node) |
172.23.1.9 |
42:44:49:00:01:09 |
svdc-t001-bbdn2 |
BigBench
(Data Node) |
172.23.1.10 |
42:44:49:00:01:10 |
svdc-t001-bbdn3 |
BigBench
(Data Node) |
172.23.1.11 |
42:44:49:00:01:11 |
svdc-t001-bbdn4 |
BigBench
(Data Node) |
172.23.1.12 |
42:44:49:00:01:12 |
svdc-t001-bbdb |
BigBench
(DBserver) |
172.23.1.13 |
42:44:49:00:01:13 |
8.6 The result (raw) file
The Raw File Generator processes the output data from the benchmark measurement to extract details about the measurement and testbed configuration. It also calculates the benchmark’s metrics. This information is collected in the raw file which is placed in the results directory for the measurement.
The raw file’s name is of the form:
specvirt-datacenter-<timestamp_from_the_result_folder>.raw
The raw file is divided into five parts, which are described in the following sections.
8.6.1 Editable data
This section of the raw file includes data that is used to generate the benchmark results HTML file (FDR) and is primarily extracted from the Testbed.config file. Since the data included here is primarily informational, post-measurement modifications to the fields within this section are allowed if corrections or additions are needed.
8.6.2 Benchmark configuration data
This section contains configuration data about the benchmark and SUT during the benchmark’s execution. Fields under this section cannot be modified, and the result is marked as invalid if any are changed. The data is extracted from the following files:
Control.config - User-defined configuration properties of the benchmark used during the measurement
startRun.config - Configuration properties of the SUT collected at the start of the benchmark measurement
endRun.config - Configuration properties of the SUT collected at the end of the benchmark measurement
8.6.3 Benchmark results data
This section contains the performance metrics and submetrics for the benchmark measurement. As above, fields under this section cannot be modified, and the result is marked as invalid if any are changed. The data is subdivided into the following areas:
Tile workload summary statistics - Individual tile’s workload summary statistics such as average response time, 90th and 95th percentile response times, throughput, and compliance information.
Result metrics and sub-metrics - Individual tile’s scores along with active tile duration information of that tile. It also includes the tile’s separate workload scores.
- Result validation checks - Detected errors in:
QoS (e.g. 90th percentile threshold exceeded)
Benchmark integrity validation (e.g. unallowed changes to parameters in Control.config)
SUT validation (e.g. invalid number of SUT hosts)
Workload-specific validation (e.g. unallowed changes to departmental workload configuration files)
8.6.4 Benchmark workload polling data
The raw file generator extracts polling data for each workload for all of the tiles for this section. Each line of polling data is in the format shown below:
log.<workload>[tile-index]:Date Time INFO [Thread-<thread-id>] <workload string>: <metric>
As above, fields under this section cannot be modified, and the result is marked as invalid if any are changed.
8.6.5 Encode data
Once all of the above data has been recorded in the results file, the svdc-director VM encodes this information and appends it to the end of the file. This provides an ability to compare the original post-measurement configuration with any post-measuement editing done on this file. The reporter uses this capability to ensure that only allowed field editing is added to any submission file created using the reporter.
As above, this section cannot be modified, and the result is marked as invalid if any are changed.
8.7 The reporter
The reporter creates result submission files from the raw file, regenerates a new raw file after post-measurement edits, and creates the formatted HTML measurement result disclosure (FDR). The svdc-director VM automatically creates the formatted HTML FDR and submission file at the end of a measurement, but the reporter must be invoked manually to regenerate submission files or edited raw files.
8.7.1 Raw file editing and regeneration
The raw file commonly requires post-measurement editing to update, correct, or clarify configuration information.
The reporter ensures that only editable values are retained in a regenerated raw or submission file using the following set of regeneration steps:
Append “.backup” to original raw file name and save it. Since the reporter overwrites the raw file passed to it, it saves the original file contents by appending the “.backup” extension to the file name.
The reporter concurrently creates the new raw file as well as the submission (.sub) file when regenerating the raw file if a raw file is passed to the reporter.
The reporter creates the new raw file if the submission (.sub) file is passed to the reporter.
Once a valid raw file and/or submission file have been generated, the reporter then uses this regenerated raw file to create the HTML-formatted final report(s).
8.7.2 Submission (sub) file generation
Invoking the reporter command generates a submission file, regardless of whether a raw file or sub file is used as input. The reporter generates a new raw file and goes through its editing and validation process, assuring and preserving only allowed edits in the newly generated raw file. Once the raw file has been recreated, the reporter then prefixes all lines not used to generate the final disclosure report file with a # character to preserve them in the submission process, and then prefixes the remaining lines with spec.virt_datacenter2021. This modified file is saved with a .sub extension, identifying it as a result file valid for submission.
Appendix A - Workload Parameters (fixed settings)
Mailserver
General settings:
VirtDatacenterLoad = true
FileDirectory = /AllInOneBench
RMIport = 8898
runtimeSeconds = 72000
logTxnsToConsole = 0
TxnDelay = 10
debugLevel=0
Individual microBench settings:
cpuCnt = 30
memCnt = 10
netCnt = 10
diskCnt = 40
CPU Test options:
CPU_stressType = zipunzip
CPU_sleepTime = 600
CPU_uncompressedBufferSizeKB = 10
CPU_numOps = 1
Memory Test options:
Mem_writeSize = 8192
Mem_readSize = 8192
Mem_workingSizeMB = 20
Mem_numReads = 2
Mem_numWrites = 2
Mem_randomReadMix = 25
Mem_randomWriteMix = 25
Mem_seqReadMix = 25
Mem_seqWriteMix = 25
Mem_sleepTime = 700
Mem_numOps = 1
Disk IO Test options:
Disk_numThreads = 4
Disk_textMixPercent = 50
Disk_textFilesPerThread = 100
Disk_fileSizeMB = 1024
Disk_sleepTime = 440
Disk_randomReadMix = 20
Disk_randomWriteMix = 30
Disk_seqReadMix = 20
Disk_seqWriteMix = 30
Disk_writeSize = 8192
Disk_readSize = 8192
Disk_numReads = 12
Disk_numWrites = 8
Disk_numOps = 1
Network Test options:
# Network_testMode options [server client mixed]
# mixed (default) = mode where allinone will act as client & server.
# server= mode where allinone will respond to network requests only
# client= mode where allinone will issue requests only.
Network_testMode = mixed
Network_serverName = localhost
Network_hostPort = 8080
Network_avgFileSizeKB = 40
Network_txnDelayMs = 50
Network_numFiles = 1000
Network_numReqs = 1
Webserver
General settings:
VirtDatacenterLoad = true
FileDirectory = /AllInOneBench
RMIport = 8898
runtimeSeconds = 36000
logTxnsToConsole = 0
TxnDelay = 10
debugLevel=0
Individual microBench settings:
cpuCnt = 10
memCnt = 20
netCnt = 0
diskCnt = 10
CPU Test options:
CPU_stressType = zipunzip
CPU_sleepTime = 500
CPU_uncompressedBufferSizeKB = 100
CPU_numOps = 1
Memory Test options:
Mem_writeSize = 8192
Mem_readSize = 8192
Mem_workingSizeMB = 20
Mem_numReads = 10
Mem_numWrites = 10
Mem_randomReadMix = 30
Mem_randomWriteMix = 20
Mem_seqReadMix = 40
Mem_seqWriteMix = 10
Mem_sleepTime = 1000
Mem_numOps = 1
Disk IO Test options:
Disk_textMixPercent = 80
Disk_textFilesPerThread = 100
Disk_fileSizeMB = 1000
#Disk_sleepTime = 10
Disk_sleepTime = 300
Disk_randomReadMix = 0
Disk_randomWriteMix = 0
Disk_seqReadMix = 80
Disk_seqWriteMix = 20
Disk_writeSize = 8192
Disk_readSize = 8192
Disk_numReads = 2
Disk_numWrites = 2
Disk_numOps = 1
Collaboration Server
General settings:
VirtDatacenterLoad = true
FileDirectory = /AllInOneBench
RMIport = 8898
runtimeSeconds = 72000
logTxnsToConsole = 0
debugLevel = 0
TxnDelay = 0
Individual microBench settings:
cpuCnt = 10
memCnt = 10
netCnt = 150
diskCnt = 20
CPU Test options:
# CPU_stressType options: [ zipunzip, mathops, mixed ] *Note, mathops and mixed not yet implemented*
CPU_stressType = zipunzip
CPU_sleepTime = 1000
CPU_uncompressedBufferSizeKB = 50
CPU_numOps = 1
Memory Test options:
Mem_writeSize = 8192
Mem_readSize = 8192
Mem_workingSizeMB = 50
Mem_numReads = 100
Mem_numWrites = 100
Mem_randomReadMix = 25
Mem_randomWriteMix = 25
Mem_seqReadMix = 25
Mem_seqWriteMix = 25
Mem_sleepTime = 700
Mem_numOps = 1
Disk IO Test options:
Disk_numThreads = 4
Disk_textMixPercent = 50
Disk_textFilesPerThread = 100
Disk_fileSizeMB = 1024
Disk_sleepTime = 340
Disk_randomReadMix = 0
Disk_randomWriteMix = 0
Disk_seqReadMix = 75
Disk_seqWriteMix = 25
Disk_writeSize = 8192
Disk_readSize = 8192
Disk_numReads = 10
Disk_numWrites = 10
Disk_numOps = 2
Network Test options:
Network_numThreads = 1
# Network_testMode options [server client mixed]
# mixed (default) = mode where allinone will act as client & server.
# server= mode where allinone will respond to network requests only
# client= mode where allinone will issue requests only.
Network_testMode = mixed
Network_serverName = svdc-t001-collab2
Network_hostPort = 8080
Network_avgFileSizeKB = 25
Network_txnDelayMs = 200
Network_numFiles = 1000
Network_numReqs = 2
HammerDB
run_hammerdb_mysql.tcl:
{
...
puts "Creating Virtual Users"
set res [rest::post http://localhost:8080/vucreate "" ]
puts $res
puts "Running Virtual Users"
set res [rest::post http://localhost:8080/vurun "" ]
puts $res
wait_for_run_to_complete $res
}
proc run_test {} {
puts "Clearscript"
set res [rest::post http://localhost:8080/clearscript "" ]
puts $res
puts "Setting Db values"
set body { "db": "mysql" }
set res [ rest::post http://localhost:8080/dbset $body ]
set body { "bm": "TPC-C" }
set res [ rest::post http://localhost:8080/dbset $body ]
puts "Destorying any old VUs"
set res [ rest::post http://localhost:8080/vudestroy "" ]
set body { "vu": "200" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
puts "Configuring VUs"
set body { "delay": "250" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
set body { "logtotemp": "1" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
set body { "showoutput": "1" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
set body { "delay": "250" }
set res [ rest::post http://localhost:8080/vuset $body ]
puts $res
puts "Setting Dict Values"
set body { "dict": "connection", "key": "mysql_host", "value": "TARGETHOST" }
set res [rest::post http://localhost:8080/diset $body ]
set body { "dict": "connection", "key": "mysql_port", "value": "3306" }
set res [rest::post http://localhost:8080/diset $body ]
set body { "dict": "tpcc", "key": "mysql_driver", "value": "timed" }
set res [rest::post http://localhost:8080/diset $body ]
set body { "dict": "tpcc", "key": "mysql_rampup", "value": "2" }
set res [rest::post http://localhost:8080/diset $body ]
set body { "dict": "tpcc", "key": "mysql_duration", "value": "60" }
set res [rest::post http://localhost:8080/diset $body ]
set body { "dict": "tpcc", "key": "mysql_keyandthink", "value": "true" }
set res [rest::post http://localhost:8080/diset $body ]
puts "Config"
set res [rest::get http://localhost:8080/dict "" ]
puts $res
puts "Loadscript"
set res [rest::post http://localhost:8080/loadscript "" ]
puts $res
puts "MySQL settings"
set res [rest::post http://localhost:8080/datagen "" ]
puts $res
puts "VU config (vuconf)"
set res [rest::post http://localhost:8080/vuconf "" ]
puts $res
puts "Create VU"
set res [rest::post http://localhost:8080/vucreate "" ]
puts "VU info"
set res [rest::post http://localhost:8080/vucreated "" ]
puts "VU status"
set res [rest::post http://localhost:8080/vustatus "" ]
puts $res
puts "Run VU"
set res [rest::post http://localhost:8080/vurun "" ]
puts $res
wait_for_run_to_complete $res
}
BigBench
The harness invokes BigBench (using a single stream) with the following command:
./bigBench runBenchmark -s 1 -f 100 >/opt/Big-Bench/logs/BigBenchOut.txt &
bigBench.properties:
workload=THROUGHPUT_TEST_1
# test will run a MAXIMUM of 6 iterations of the "13 queries" (see below)
throughput_test_1_0=1,3,6,7,8,12,13,16,19,20,29,1,3,6,7,8,12,13,16,19,20,29,1,3,6,7,8,12,13,16,19,20,29,
1,3,6,7,8,12,13,16,19,20,29,1,3,6,7,8,12,13,16,19,20,29,1,3,6,7,8,12,13,16,19,20,29
userSettings.conf:
# Copyright 2015-2019 Intel Corporation.
# This software and the related documents are Intel copyrighted materials, and your use of them
# is governed by the express license under which they were provided to you ("License"). Unless the
# License provides otherwise, you may not use, modify, copy, publish, distribute, disclose or
# transmit this software or the related documents without Intel's prior written permission.
#
# This software and the related documents are provided as is, with no express or implied warranties,
# other than those that are expressly stated in the License.
## ==========================
## JAVA environment
## ==========================
export BIG_BENCH_JAVA="java"
export HIVE_HOME="/opt/createApacheCluster/hive"
## ==========================
## common query resources
## ==========================
export BIG_BENCH_QUERY_RESOURCES="${BIG_BENCH_HOME}/distributions/Resources"
## ==========================
## default settings for benchmark
## ==========================
export BIG_BENCH_DEFAULT_DATABASE="bigbenchORC"
export BIG_BENCH_DEFAULT_DISTRO_LOCATION="cdh/6.0"
export BIG_BENCH_DEFAULT_ENGINE="hive"
export BIG_BENCH_DEFAULT_MAP_TASKS="80"
export BIG_BENCH_DEFAULT_SCALE_FACTOR="10"
export BIG_BENCH_DEFAULT_NUMBER_OF_PARALLEL_STREAMS="2"
export BIG_BENCH_DEFAULT_BENCHMARK_PHASE="run_query"
## ==========================
## HADOOP environment
## ==========================
##folder containing the cluster setup *-site.xml files like core-site.xml
export BIG_BENCH_HADOOP_CONF="/etc/hadoop/conf.cloudera.hdfs"
export BIG_BENCH_HADOOP_LIBS_NATIVE="/opt/cloudera/parcels/CDH/lib/hadoop/lib/native"
## ==========================
## HDFS config and paths
## ==========================
export BIG_BENCH_USER="$USER"
export BIG_BENCH_HDFS_ABSOLUTE_PATH="/user/$BIG_BENCH_USER" ##working dir of benchmark.
export BIG_BENCH_HDFS_RELATIVE_HOME="benchmarks/bigbench"
export BIG_BENCH_HDFS_RELATIVE_INIT_DATA_DIR="$BIG_BENCH_HDFS_RELATIVE_HOME/data"
export BIG_BENCH_HDFS_RELATIVE_REFRESH_DATA_DIR="$BIG_BENCH_HDFS_RELATIVE_HOME/data_refresh"
export BIG_BENCH_HDFS_RELATIVE_QUERY_RESULT_DIR="$BIG_BENCH_HDFS_RELATIVE_HOME/queryResults"
export BIG_BENCH_HDFS_RELATIVE_TEMP_DIR="$BIG_BENCH_HDFS_RELATIVE_HOME/temp"
export BIG_BENCH_HDFS_ABSOLUTE_HOME="$BIG_BENCH_HDFS_ABSOLUTE_PATH/$BIG_BENCH_HDFS_RELATIVE_HOME"
export BIG_BENCH_HDFS_ABSOLUTE_INIT_DATA_DIR="$BIG_BENCH_HDFS_ABSOLUTE_PATH/$BIG_BENCH_HDFS_RELATIVE_INIT_DATA_DIR"
export BIG_BENCH_HDFS_ABSOLUTE_REFRESH_DATA_DIR="$BIG_BENCH_HDFS_ABSOLUTE_PATH/$BIG_BENCH_HDFS_RELATIVE_REFRESH_DATA_DIR"
export BIG_BENCH_HDFS_ABSOLUTE_QUERY_RESULT_DIR="$BIG_BENCH_HDFS_ABSOLUTE_PATH/$BIG_BENCH_HDFS_RELATIVE_QUERY_RESULT_DIR"
export BIG_BENCH_HDFS_ABSOLUTE_TEMP_DIR="$BIG_BENCH_HDFS_ABSOLUTE_PATH/$BIG_BENCH_HDFS_RELATIVE_TEMP_DIR"
# --------------------------------------------
# Hadoop data generation options
# --------------------------------------------
# specify JVM arguments like: -Xmx2000m;
# default of: 800m is sufficient if the datagen only uses "-workers 1" - one worker thread per map task
# Add +100MB per additional worker if you modified: BIG_BENCH_DATAGEN_HADOOP_OPTIONS
export BIG_BENCH_DATAGEN_HADOOP_JVM_ENV="$BIG_BENCH_JAVA -Xmx800m"
# if you increase -workers, you must also increase the -Xmx setting in BIG_BENCH_DATAGEN_HADOOP_JVM_ENV;
# -ap:=automatic progress ,3000ms intervall; prevents hadoop from killing long running jobs.
# Datagen runs piggyback on a map task as external process. If the ex$-workers:=limit hadoop based
# data generator to use 1 CPU core per map task.
export BIG_BENCH_DATAGEN_HADOOP_OPTIONS=" -workers 1 -ap 3000 "
#replication count for staging data files written by the data generator during DATA_GENERATION phase of the benchmark into HDFS directories:
#BIG_BENCH_HDFS_ABSOLUTE_INIT_DATA_DIR and BIG_BENCH_HDFS_ABSOLUTE_REFRESH_DATA_DIR
#recommended: =-1 -- use cluster default (typical HDFS default is =3)
# =1 -- to save space,
# =3 -- or any number you like
export BIG_BENCH_DATAGEN_DFS_REPLICATION="1"
# if empty, generate all tables (default).
# Else: explicitly specify which tables to generate e.g.: BIG_BENCH_DATAGEN_TABLES="item customer store"
# Tables to choose from: customer customer_address customer_demographics date_dim household_demographics income_band inventory item item_marketprices product_r$
export BIG_BENCH_DATAGEN_TABLES=""
# if distributed data generation fails, re run DATA_GENERATION phase with BIG_BENCH_DATAGEN_HADOOP_EXEC_DEBUG="-testDebugMessages" to retrieve more information
export BIG_BENCH_DATAGEN_HADOOP_EXEC_DEBUG=""
# the default behaviour is to stop the whole benchmark when an error occurs
# set this to 0 to keep on running (e.g. continue with next phase or query) when an error occurs
export BIG_BENCH_STOP_AFTER_FAILURE="1"
## Speed up HDFS operations like copy, move, delete, list, chmod, mkdir
## requires "snakebite" to be installed https://github.com/spotify/snakebite
## yum install epel-release
## yum install -y python-pip
## pip install snakebite
#0==off 1==on
export BIG_BENCH_USE_SNAKEBITE_HDFSCLIENT="0"
# set binary name of pssh for environment information gathering
# used to retrieve statistics and information from worker nodes
export BIG_BENCH_PSSH_BINARY="pssh"
Appendix B - Example run.xml benchmark test run/control definition (one tile test)
run.xml:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!-- Note: Some parameters have not yet been implemented -->
<cloudperf>
<event-config>
<event type="action" class="timed" tag="SUT startRunScript" time="1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">startRun.sh</parameter>
<parameter name="environment">common</parameter>
</action>
</event>
<event type="action" class="timed" tag="Deploy T001 Mail" time="10" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">DeployVM-AIO.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-mail</parameter>
<parameter name="arg2">42:44:49:00:01:01</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start Mail Tile 001" time="+1" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="hostname">svdc-t001-mail</parameter>
<parameter name="start">mail</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Deploy T001 Web" time="+15" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">DeployVM-AIO.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-web</parameter>
<parameter name="arg2">42:44:49:00:01:02</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start WebSUT Tile 001" time="+1" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="hostname">svdc-t001-web</parameter>
<parameter name="start">webSUT</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Start AIO Service Client 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">startAIO_Service-Tile.sh</parameter>
<parameter name="environment">common</parameter>
<parameter name="arg1">1</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start Web Client Tile 001" time="+5" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="hostname">svdc-t001-client</parameter>
<parameter name="start">webclient</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Deploy T001 Collab1" time="+15" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">DeployVM-AIO.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-collab1</parameter>
<parameter name="arg2">42:44:49:00:01:03</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start Collab1 Tile 001" time="+1" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="hostname">svdc-t001-collab1</parameter>
<parameter name="start">collab</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Deploy T001 Collab2" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">DeployVM-AIO.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-collab2</parameter>
<parameter name="arg2">42:44:49:00:01:04</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start Collab2 Tile 001" time="+1" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="hostname">svdc-t001-collab2</parameter>
<parameter name="start">collab</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="PowerON VM HammerApp Tile 001" time="+15" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-happ</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerON VM HammerDB Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-hdb</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start HammerDB Tile 001" time="+1" level="2">
<driver name="HammerDBAgent_T001">
<load>
<parameter name="start">1</parameter>
<parameter name="remainingTime">1443</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="PowerOn BigBench DB Tile 001" time="+60" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbdb</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerOn BigBench NameNode Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbnn</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerOn BigBench DN1 Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbdn1</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerOn BigBench DN2 Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbdn2</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerOn BigBench DN3 Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbdn3</parameter>
</action>
</event>
<event type="action" class="timed" tag="PowerOn BigBench DN4 Tile 001" time="+1" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">PowerOnVM.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">svdc-t001-bbdn4</parameter>
</action>
</event>
<event type="load" class="timed" tag="Start BigBench Tile 001" time="+1" level="2">
<driver name="BigBenchAgent_T001">
<load>
<parameter name="start">1</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Add Offline Host: 172.23.0.14" time="610" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">ExitMaintenanceMode.sh</parameter>
<parameter name="environment">vSphere</parameter>
<parameter name="arg1">172.23.0.14</parameter>
</action>
</event>
<event type="action" class="timed" tag="Phase 3 Start" time="910" level="2">
<action name="GenericOp" service="HV">
<parameter name="scriptName">NoOp.sh</parameter>
<parameter name="environment">common</parameter>
</action>
</event>
<event type="load" class="timed" tag="Stop AIO Tile 001" time="1810" level="2">
<driver name="AllInOneAgent_T001">
<load>
<parameter name="stopall">1</parameter>
</load>
</driver>
</event>
<event type="load" class="timed" tag="Stop HammerDB Tile 001" time="+1" level="2">
<driver name="HammerDBAgent_T001">
<load>
<parameter name="stop">1</parameter>
</load>
</driver>
</event>
<event type="load" class="timed" tag="Stop BB Tile 001" time="+1" level="2">
<driver name="BigBenchAgent_T001">
<load>
<parameter name="stop">1</parameter>
</load>
</driver>
</event>
<event type="action" class="timed" tag="Calling endRun" time="+1" level="2" dependency="endRun">
<action name="GenericOp" service="HV">
<parameter name="scriptName">endRun.sh</parameter>
<parameter name="environment">common</parameter>
</action>
</event>
<event type="stop" class="timed" tag="Finish_WITH_ENDRUN_ERROR!!" depends="!endRun"></event>
<event type="action" class="timed" tag="User exitScript" depends="endRun" level="2" dependency="exitScript">
<action name="GenericOp" service="HV">
<parameter name="scriptName">userExit.sh</parameter>
<parameter name="environment">vSphere</parameter>
</action>
</event>
<event type="stop" class="timed" tag="Finish" depends="exitScript"></event>
<event type="stop" class="timed" tag="Finish_with_EXIT_SCRIPT_ERROR!" depends="!exitScript"></event>
</event-config>
</cloudperf>