|
SGI |
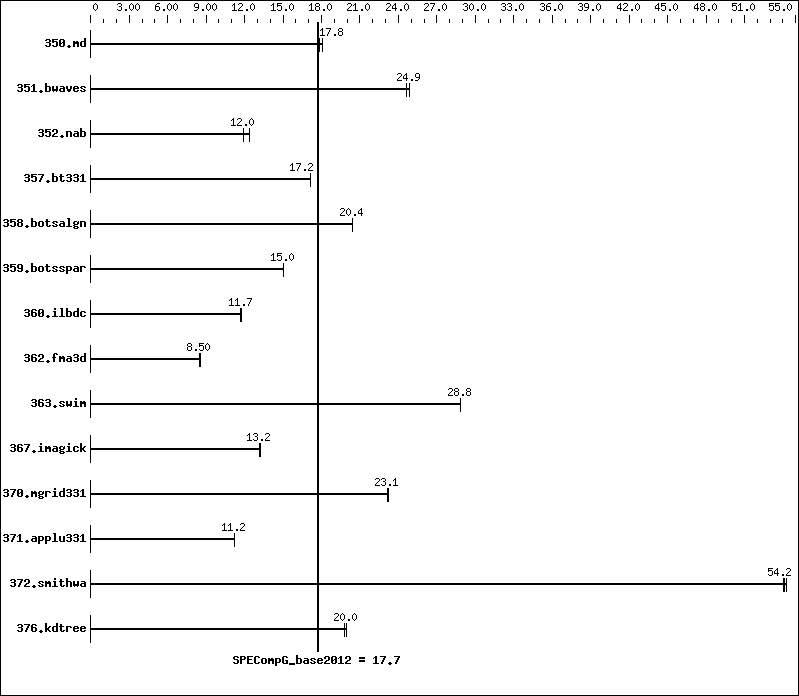
SPECompG_base2012 = 17.7 |
|
SGI UV1000 (Intel Xeon E7-8837, 2.66GHz) |
SPECompG_peak2012 = Not Run |
| OMP2012 license: | 14 | Test date: | Sep-2012 |
|---|---|---|---|
| Test sponsor: | SGI | Hardware Availability: | Apr-2011 |
| Tested by: | SGI | Software Availability: | Aug-2012 |
| Hardware | |
|---|---|
| CPU Name: | Intel Xeon E7-8837 |
| CPU Characteristics: | Intel Turbo Boost Technology up to 2.80 GHz |
| CPU MHz: | 2667 |
| CPU MHz Maximum: | 2800 |
| FPU: | Integrated |
| CPU(s) enabled: | 128 cores, 16 chips, 8 cores/chip |
| CPU(s) orderable: | 2-256 chips |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 256 KB I+D on chip per core |
| L3 Cache: | 24 MB I+D on chip per chip |
| Other Cache: | None |
| Memory: | 512 GB (128 x 4 GB 4Rx8 PC3-8500R-7, ECC) |
| Disk Subsystem: | 10 x 1 TB SAS (Seagate Constellation ES, 7200RPM) |
| Other Hardware: | Routered quad-plane fat tree topology |
| Base Threads Run: | 128 |
| Minimum Peak Threads: | -- |
| Maximum Peak Threads: | -- |
| Software | |
|---|---|
| Operating System: | SUSE Linux Enterprise Server 11 (x86_64) SP1 2.6.32.46-0.3.1.3592.0.PTF-default |
| Compiler: | C/C++/Fortran: Version 13.0 of Intel Composer XE 2013 Build 20120731 |
| Auto Parallel: | No |
| File System: | xfs |
| System State: | Run level 3 ( Multi-user ) |
| Base Pointers: | 64-bit |
| Peak Pointers: | Not Applicable |
| Other Software: | sgi-accelerate-release: SGI Accelerate 1.3, Build 705rp1.sles11-1110302109 sgi-foundation-release: SGI Foundation Software 2.5, Build 705rp1.sles11-1110302109 |
Results Table
| Benchmark | Base | Peak | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Threads | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | Threads | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | |
| Results appear in the order in which they were run. Bold underlined text indicates a median measurement. | ||||||||||||||
| 350.md | 128 | 260 | 17.8 | 256 | 18.1 | 260 | 17.8 | |||||||
| 351.bwaves | 128 | 182 | 24.9 | 182 | 24.9 | 184 | 24.6 | |||||||
| 352.nab | 128 | 325 | 12.0 | 325 | 12.0 | 315 | 12.3 | |||||||
| 357.bt331 | 128 | 276 | 17.2 | 276 | 17.2 | 276 | 17.2 | |||||||
| 358.botsalgn | 128 | 213 | 20.4 | 213 | 20.4 | 213 | 20.4 | |||||||
| 359.botsspar | 128 | 349 | 15.0 | 350 | 15.0 | 349 | 15.0 | |||||||
| 360.ilbdc | 128 | 304 | 11.7 | 303 | 11.7 | 303 | 11.7 | |||||||
| 362.fma3d | 128 | 444 | 8.55 | 448 | 8.48 | 447 | 8.50 | |||||||
| 363.swim | 128 | 157 | 28.8 | 157 | 28.9 | 157 | 28.8 | |||||||
| 367.imagick | 128 | 534 | 13.2 | 532 | 13.2 | 534 | 13.2 | |||||||
| 370.mgrid331 | 128 | 191 | 23.2 | 191 | 23.1 | 191 | 23.1 | |||||||
| 371.applu331 | 128 | 540 | 11.2 | 542 | 11.2 | 540 | 11.2 | |||||||
| 372.smithwa | 128 | 98.8 | 54.3 | 99.2 | 54.0 | 99.0 | 54.2 | |||||||
| 376.kdtree | 128 | 228 | 19.8 | 225 | 20.0 | 225 | 20.0 | |||||||
Submit Notes
The config file option 'submit' was used.
General Notes
Software Environment:
export KMP_AFFINITY=disabled
export KMP_STACKSIZE=200M
export KMP_SCHEDULE=static,balanced
export OMP_DYNAMIC=FALSE
limit -s unlimited
For all benchmarks threads were bound to cores using
the following submit command:
dplace -x2 $command
This binds threads in order of creation, beginning
with the master thread on logical cpu 0, the first slave
thread on logical cpu 1, and so on. The -x2 flag instructs
dplace to skip placement of the lightweight OpenMP monitor
thread, which is created prior to the slave threads.
Base Portability Flags
| 350.md: | -free |
| 367.imagick: | -std=c99 |