|
|
SPEC SIP Design DocumentRevision Date: September 6th, 2007
1 Overview of SPEC SIPSPECSIP2008 is a software benchmark product developed by the Standard Performance Evaluation Corporation (SPEC), a non-profit group of computer vendors, system integrators, universities, research organizations, publishers, and consultants. It is designed to evaluate a system's ability to act as a SIP server supporting a particular SIP application. For SPEC SIP 2008, the application modeled is a VoIP deployment for an enterprise, telco, or service provider, where the SIP server performs proxying and registration. This document overviews the design of SPEC SIP 2008, including design principles, included and excluded goals, the structure and components of the benchmark, the chosen workload, and reasons behind various choices. Separate documents will discuss specifics of how to build and run the benchmark. Multiple documents exist to describe different aspects of the benchmark. These include:
The remainder of this document discusses the design of the SPEC SIP benchmark. We assume the reader is aware of core SIP terminology provided by IETF's RFC 3261, available at http://www.ietf.org/rfc/rfc3261.txt. In addition, the reader should be aware of Malas' "SIP End-to-End Performance Metrics" draft, currently available at http://www.ietf.org/internet-drafts/draft-ietf-pmol-sip-perf-metrics-00.txt.
1.1 Design PrinciplesThe main principle behind the design of the SPEC SIP 2008 benchmark is to emulate SIP user behavior in a realistic manner. Users are the main focus of how SIP traffic is generated. This means defining a set of assumptions for how users behave, applying these assumptions through the use of profiles, and implementing the benchmark to reproduce and emulate these profiles. These assumptions are made more explicit in the next section.
1.2 Requirements and GoalsThe primary requirement and goal for SPEC SIP is to evaluate SIP server systems as a comparative benchmark in order to aid customers. The main features are:
The last feature illustrates a secondary additional goal, which is to aid in capacity planning and provisioning of systems. SPEC SIP explicitly defines a standard workload, which consists of standard SIP scenarios (what SIP call flows happen) and the frequency with which they happen (the traffic profile). Different environments (e.g., ISP, Telco, University, Enterprise) clearly have different behaviors and different frequencies of events. SPEC SIP is designed to be configurable so as to allow easy modification of the benchmark for use in customer engagements so that the traffic profile and resulting generated workload can be adapted to more closely match a particular customer's environment. Towards this end, we make traffic profile variables explicit to allow customization. However, for publishing numbers with SPEC, the standard SPEC SIP benchmark with the standard traffic profile must be used.
1.3 Excluded GoalsDue to time, complexity, and implementation issues, the SPEC SIP benchmark is necessarily limited. Goals that are excluded in this release of the benchmark include:
Assumptions are listed in detail in Section 2.5.
2 Component OutlinesThe SPEC SIP 2008 Benchmark consists of several logical components that make up the benchmark. This section provides a high-level view of the architecture for how these components fit together and interact with each other.
2.1 Logical Architecture The above Figure shows the logical architecture for how the components of the benchmark system fit together. The benchmark system simulates a group of SIP end point users who perform SIP operations through the System Under Test (SUT).
2.2 SUT (SIP Server for an Application)The System Under Test (SUT) is the combination of hardware and software that provides the SIP application (in this case, VoIP) that the benchmark stresses. The SUT is not part of the SPEC benchmark suite, but is provided by hardware and/or software vendors wishing to publish SIP performance numbers. The SUT performs both SIP stateful proxying that forwards SIP requests and responses between users and registration that records user location provided by users via the REGISTER request. The SUT receives, processes and responds to SIP messages from the client SIP load drivers (UAC, UAS, and UDE, described below). In addition, it logs SIP transaction information to disk for accounting purposes. The SUT exposes a single IP address as the interface for communication. More extensive details about the SUT (namely, requirements) are given in Section 5.1.
2.3 Clients (Workload Generators/Consumers)Clients emulate the users sending and receiving SIP traffic. Per the SIP RFC notion of making client-side versus server-side behavior explicit and distinct, a user is represented by three SIP components, each of which both sends and receives SIP packets depending on its role.
While the User Device Emulator (UDE) is technically a UAC in SIP RFC terms, we explicitly distinguish it from the UAC here that makes phone calls so as to avoid confusion. Each User-Agent component above is defined by a user or device model that specifies test scenarios and user behaviors, described in more detail in Section 4.4.
2.4 Benchmark HarnessThe Benchmark harness is responsible for coordinating the test: starting and stopping multiple client workload generators; collecting and aggregating the results from the clients; determining if a run was successful and displaying the results. It is based on FABAN framework and is described in more detail in Section 7.
2.5 AssumptionsWe make the following assumptions about the environment for the benchmark:
3 Performance MetricsThis section describes the primary and secondary metrics that SPEC SIP 2008 measures.
3.1 Primary MetricThe primary metric for SPEC SIP is simultaneous number of conforming users, where a user is a statistical model of user behavior, specified below. Conforming means satisfying the QoS requirements, also to be specified below. A user includes both
While a user could potentially be represented by multiple devices simultaneously, for simplicity in the benchmark, there is only one device per user.
3.2 QoS DefinitionsSince SIP is a protocol for interactive media sessions, responsiveness is an important characteristic for providing good quality of service (QoS). For a SPEC SIP benchmark run to be valid, 99.99 percent ("4 nines") of transactions throughout the lifetime of the test must be successful. The definition of a successful transaction is:
A transaction that does not satisfy the above is considered a failed transaction. Examples of a failed transaction include a transaction timeout or a 503 (Service Unavailable) response. In addition, for a test to be valid, it must comply with the following requirements:
The idea behind these requirements is that the SUT must provide both correct and timely responses. Most responses should complete without SIP-level retransmissions (the 95 percent requirement) but a small number may incur one retransmission (Timer A). The session request delay does include the time for the SUT to interact with the UAS. We thus expect those running the benchmark will provision the UAS machines sufficiently so that the response time contributed by the UAS is negligible. We also expect the same to be true of the network, which will likely be an isolated high-bandwidth LAN. The bulk of the SRD should thus be composed of service and queuing time on the SUT, not service or queuing time on the UAC, UAS or network.
3.3 Secondary MetricsSecondary metrics are reported to help describe the behavior of the test that has completed. They include:
4 Workload DescriptionAs described earlier, the modeled application is a VoIP deployment in an enterprise, telco, or service provider context. Users make calls, answer them, and talk. Devices also act on behalf of users by periodically registering their location. Additional details of the SPEC SIP workload include:
4.1 Scaling Definition: Number of UsersSince the primary performance metric is the number of simultaneous conforming users, the way load in the benchmark is increased is by adding users. Each instantiated user implies an instantied UAC, UAS, and UDE for that user.
4.2 Traffic Profile (Scenario Probabilities)This section defines the SIP transaction scenarios that make up the traffic profile, for both users making calls and devices making registrations. Registration scenarios are executed by the UDE. Calling scenarios are executed by the UAC and UAS acting together.
While the SPEC SIP subcommittee considered the scenario where a device does not authenticate successfully due to a bad password, we believe that scenario is so infrequent so as to not be worth including in the benchmark.
The final two call scenarios, rejected call and failed call, were considered by the SPEC SIP subcommittee but rejected since they did not seem to be frequent enough to warrant including. The reject call scenario (busy signals) appears to be a relic of the past, since when a user is on the phone the call is routed to voicemail rather than rejected with a busy signal. Similarly, failed call appears to be obsolete since when a non-working extension is dialed, the user is connected to a machine that plays the message "you have reached an invalid extension at XYZ Corporation." For these reasons, the last two scenarios are not included in the traffic profile, since they effectively map to completed calls to a voicemail-like service, and thus the impact on the SUT is similar to a voicemail call. Future versions of the benchmark may revisit these decisions if, for example, real traffic studies show these scenarios contribute a non-trivial amount of traffic in a VoIP environment.
4.3 Traffic ParametersThis section defines the traffic parameters used by the user and device models. Durations are periods of time taken for particular events, for example, CallDuration. Most durations are parameterized distributions but are occasionally fixed, constant values.
4.4 User and Device ModelsUser models are meant to capture the way in which a user interacts with the SIP protocol stack below. User behavior is represented using a standard workflow model, where users take programmatic steps and make decisions that cause branching behavior. Steps are in terms what the user does, rather than what the SIP protocol does. User steps may trigger particular SIP call flows that depend on the action taken; however, the actions taken at the SIP protocol layer occur ``below'' the user behavior layer. Thus, for example, a step may say "make a call" but will not enumerate the packet exchanges for the INVITE request. Device models serve a similar function, but are intended to capture the way a device behaves, where a device is some piece of software or hardware utilized by the user, e.g., a hard phone, a soft phone, or IM client software. They are typically used to model periodic behavior by the device. For example, two packet traces of SIP software show that a common value for registration is to register with a 15 minute timeout value, and then re-register at 10 minute intervals, so that the registration does not expire. These periodic values are not defined by the SIP protocol; thus, they represent some opportunity for a developer to make an arbitrary decision. Note that the device model is meant to capture a common-case decision made by these developers.
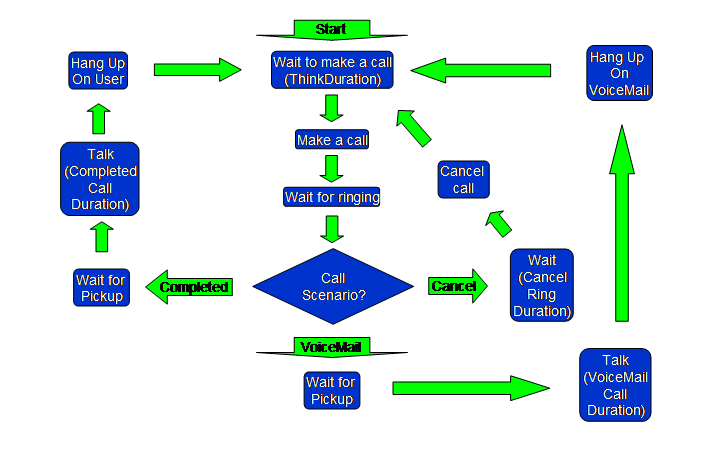
4.4.1 UAC User Model The above Figure shows the user model for the UAC. Note that the UAC makes
the decision of which call scenario is being performed (Completed, VoiceMail,
Canceled), and communicates that information via the
4.4.2 UAS User Model The above Figure shows the user model for the UAS. Note that the UAS
must know which call scenario is being performed, and receives this information
from the UAC via the
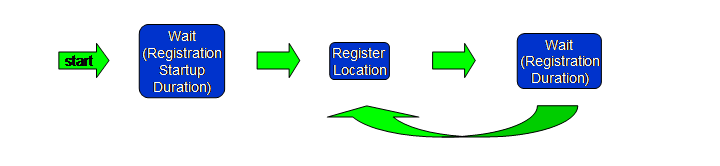
4.4.3 UDE Device Model The above Figure shows the user model for the UDE.
4.5 Use Case Scenarios
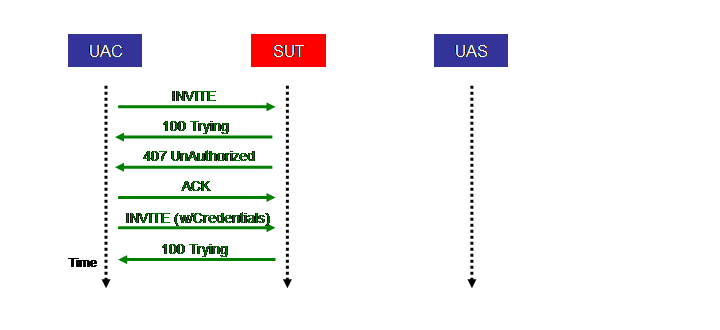
4.5.1 Registration Scenario 1: Successful RegistrationThis scenario models the process of user registration in a SIP environment. Registration is common to many SIP applications. Each user has a unique public SIP identity, and must be registered and authenticated to the SUT before being able to receive any messages. Through registration, each user binds its public identity to an actual UA SIP address (i.e., IP address and port number). In general, SIP allows multiple addresses to be registered for each user. In the benchmark, however, for simplicity, a maximum of one such UA address is allowed to be registered for a single public identity. The above Figure shows the call flow for the successful registration scenario, which proceeds as follows:
In general, it is possible in some cases to cache the nonce that is used in the challenge, so that the Authorization header can be re-used on later SIP request without necessitating going through the 401 response above. However, for security reasons, the nonce is valid for only a limited period of time. SPEC SIP assumes that any nonce would have expired and thus the authorization exchange above is necessary for each transaction.
4.5.2 Call Scenario 1: Completed Call The above Figure shows the call flow of the first stage of the INVITE part of the Completed call scenario. The message flow is as follows:
The above Figure shows the call flow of the second stage of the INVITE part of the Completed call scenario. It proceeds as follows:
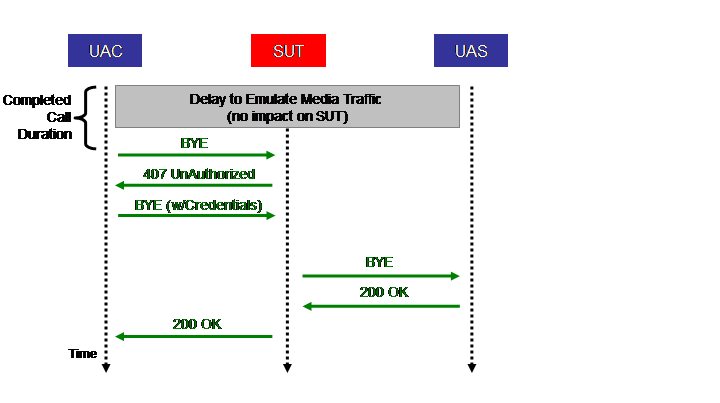
The above Figure shows the call flow of the BYE part of the Completed call scenario. It proceeds as follows:
4.5.3 Call Scenario 2: VoiceMail Call The above Figure shows the call flow of the first stage of the VoiceMail call scenario. It is identical to the first part of the Completed call scenario in Section 4.3.2. For that reason we do not repeat the description of the steps here. The above Figure shows the second part of the VoiceMail call scenario. It proceeds as follows:
The remainder of the callflow is a standard SIP session setup and teardown between the UAC and the voicemail server, which acts as a UAS. Since the remainder of the callflow does not involve the SUT, it is not shown. This is similar to Section 6.2 in RFC 4458. The session setup and teardown between the UAC and the voicemail server does not need to be implemented by the UAC in practice. The VoiceMailCallDuration, however, must be implemented by the UAC, since it contributes to the time before the UAC generates the next call.
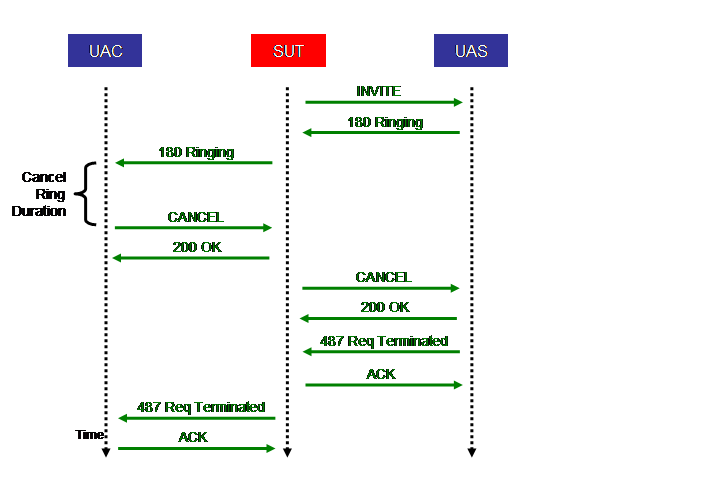
4.5.4 Call Scenario 3: Canceled Call The above Figure shows the call flow of the first stage of the INVITE part of the Canceled call scenario. It is identical to the first part of the Completed call scenario in Section 4.3.2. For that reason we do not repeat the description of the steps here. The above Figure shows the call flow for the remainder of the Canceled call scenario. It proceeds as follows:
While it is possible for race conditions to occur (e.g., the UAS picks up before the CANCEL request arrives at the UAS), for simplicity, these are not modeled by SPEC SIP.
5 Client Workload Generator DetailsSIPp is used as a load driver to generate, receive and respond to SIP messages. SIPp is a de facto standard workload generator for SIP and is available via Open Source at http://sipp.sourceforge.net/. SIPp supports a wide array of features including:
SIPp is programmable; its behavior is controlled by an XML scenario file in which a user or device model is specified as a series of messages to be sent and expected responses to be received. As an example, three logical instantiations of SIPp are required for the benchmark, each of which implements one portion of the user/device model:
Each portion is implemented via a specific SIPp XML file. SIPp also supports reporting results at predetermined intervals using a statistics file. The statistics file is like a CSV file, but is delimited by semicolons rather than commas. The statistics file displays the number of created calls, successful calls, failed calls, and response time distributions.
6 SUT DetailsThe SUT providing the VoIP application is responsible for user location registration, call routing, authentication, and state management. It is a proxy and registrar application that receives, processes and responds to SIP messages from the load drivers (UAC, UAS, and UDE). In addition, it also retrieves and archives the user’s registration information and accounting information. It must, of course, conform to RFC 3261.
6.1 SUT AccountingThe SUT is required to log all SIP transactions to disk during the run for accounting and administrative purposes. It also enables billing and aids in management and capacity planning. This log will be required to be provided to the SPEC SIP SubCommittee for publishing performance results. The format of the log is not specified; instead, the following information is required to be in the log, in any format chosen by the SUT (e.g., in compressed format). When results are submitted, a script must be provided that transforms the log into text that can be analyzed (e.g., a perl or awk script). The following information is logged for every SIP transaction:
Implied Type means the type of the record that will be produced by the script when processed on the transaction log. It does not mean that the log must specifically use that type. For example, one can imagine using a single byte to encode a transaction type, rather than a variable-length string, for efficiency. Each SIP transaction generates a log entry for that particular transaction: INVITE, BYE, CANCEL, and REGISTER. ACK requests do not need to be logged, since they are considered part of the INVITE transaction. Similarly, authentication challenges do not need to be logged, such as the initial REGISTER request that is challenged with a 401 (Unauthorized) response. Only the successful REGISTER transaction that completes with a 200 (OK) response needs to be logged. TransactionType is the SIP transaction being logged. In this test, it will always be INVITE, BYE, CANCEL, or REGISTER. FinalResponse is the final response code (200 or greater) for the transaction. In this test, it should always be 200 (OK), 302 (Moved Temporariliy) or 487 (Request Terminated). FromUser is the user the request originates from (the caller). ToUser is the user the request is destined to (the callee). Call-ID is the Call-ID: used in the transaction which uniquely identifies the call. Time is the absolute time when the event occurred in milliseconds. The idea is that given a stream of events, a provider can produce accounting information by running a post-processing step on the log and reconciling items. This is why the Call-ID is included: to match an INVITE transaction with the matching BYE or CANCEL transaction. Given this information, for example, call duration can be calculated and the appropriate accounting/billing performed.
7 Harness DetailsThe harness is an infrastructure that automates the benchmarking process. It provides an interface for scheduling and launching benchmark runs. It also offers extensive functionality for viewing, comparing and charting results. The harness consists of two types of components: master and client. The above Figure shows a more detailed version of the logical architecture presented in Section 2.1. It shows how the harness master communicating with the harness clients, which are co-located with and control the SIPp instances that provide the UAC, UAS, and UDE workload generators. The harness master is the node that controls the experimental setup. It contains a Web server, a run queue, a log server and a repository of benchmark code and results. The master may run on a client machine or on a separate machine. The Web server facilitates access to the harness for submitting and managing runs, as well as accessing the results. The run queue is the main engine for scheduling and controlling benchmark runs. The log server receives logs from all clients in near real time and records them. The harness client invokes and controls each workload generator. It communicates with the master for commands to deploy the configuration to the workload generators, and to collect benchmark results, system information and statistics.
7.1 Benchmark ConfigurationTo run a benchmark, the user first configures the run through the master. The configuration includes two components: clients and workload.
7.1.1 Client ConfigurationCertain client information will be specified by SPEC SIP and is not modifiable by the user:
Other information is specific to an environment and must be specified by the user:
7.1.2 Workload ConfigurationAgain, certain components are specified by the benchmark and are not modifiable by the user:
Others are specified by the user:
7.2 Run Management and ValidationOnce the benchmark configuration is complete, the user can submit the run request to the master and the request will be put into a queue. If there are no existing requests, the benchmark run will start immediately, otherwise it must wait until all previous requests are completed or canceled. The user can kill the current run or cancel any run in the queue via the Web interface. Once the benchmark starts, the master first disseminates configuration information to to all systems, starts all performance data collection tools on all client systems, initiates and commands all clients to start at once. The harness records each step of the run in a log. Once a run is complete, the master collects logs and statistics from all clients, and processes and compiles them into reports. The logs from load generators will be analyzed and checked against the run rules to determine whether a run is valid as specified in Section 3, and matches the traffic profile as specified in Section 4. The harness will then store a summary, a detailed report, the run configuration and the logs in its repository.
8 Summary and ConclusionThis is the first version of SPEC SIP benchmark. As such, we have attempted to keep the design simple, representative, and consistent with the SIP specification. We expect to release improved versions of the benchmark in the future, reflecting better understanding of real-world workloads and experience in running the benchmark itself. We encourage constructive feedback for improving the SPEC SIP benchmark. This document is Copyright SPEC 2007. This document shall not be construed as a commitment to develop a benchmark. Home - Contact - Site Map - Privacy - About SPEC 


webmaster@spec.org 
Last updated: Tue Mar 25 18:57:29 EDT 2008 Copyright 1995 - 2024 Standard Performance Evaluation Corporation URL: http://www.spec.org/sipinf2010/docs/design-document.html |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||