SPECsfs2008_nfs.v3 Result
|
NetApp, Inc.
|
:
|
Data ONTAP 8.1 Cluster-Mode (8-node FAS6240)
|
|
SPECsfs2008_nfs.v3
|
=
|
512667 Ops/Sec (Overall Response Time = 1.54 msec)
|
Performance
Throughput
(ops/sec)
|
Response
(msec)
|
|
51014
|
0.6
|
|
102141
|
0.8
|
|
153324
|
0.9
|
|
204422
|
1.1
|
|
255905
|
1.3
|
|
306885
|
1.4
|
|
358529
|
1.7
|
|
410199
|
2.2
|
|
462245
|
3.0
|
|
512667
|
4.8
|
|

|
Product and Test Information
|
Tested By
|
NetApp, Inc.
|
|
Product Name
|
Data ONTAP 8.1 Cluster-Mode (8-node FAS6240)
|
|
Hardware Available
|
Nov 2010
|
|
Software Available
|
Sept 2011
|
|
Date Tested
|
Sept 2011
|
|
SFS License Number
|
33
|
|
Licensee Locations
|
Sunnyvale, CA USA
|
Data ONTAP 8.1 Cluster-Mode extends the storage domain of a high-availability (HA) pair of controllers to multiple pairs of controllers. With Data ONTAP 8.1 Cluster-Mode, capacity scales from terabytes to tens of petabytes, all transparent to your running applications. Your storage is virtualized across as many as 24 nodes, managed as a single logical pool of resources and name space. Virtualizing your storage across multiple pairs of controllers provides nearly limitless scalability for even the most data-intensive environments, regardless of network protocol, SAN or NAS. Data ONTAP 8.1 offers the first massively scalable unified storage platform with support for FC, iSCSI, FCoE, NFS and CIFS.
Configuration Bill of Materials
|
Item No
|
Qty
|
Type
|
Vendor
|
Model/Name
|
Description
|
|
1
|
8
|
Storage Controller
|
NetApp
|
FAS6240
|
FAS6240 with SAS CTRL and IO Expander
|
|
2
|
8
|
4-port SAS IO card
|
NetApp
|
IO Board SAS 4-port X2067-R6
|
4-port SAS IO Card
|
|
3
|
24
|
Disk Shelves with SAS Disk Drives
|
NetApp
|
DS4243-1511-24S-R5-C
|
DS4243 disk shelf with 24x450GB, 15K, SAS HDD
|
|
4
|
8
|
Flash Cache Module
|
NetApp
|
PAMII-512-R5
|
Flash Cache Module 512GB
|
|
5
|
1
|
Software license
|
NetApp
|
SW-6240-Cluster License
|
Data ONTAP 8.1 Cluster mode License
|
|
6
|
1
|
Software License
|
NetApp
|
SW-6240-NFS
|
NFS Software license SW-6240-NFS
|
|
7
|
2
|
Network Switch
|
Cisco
|
Cisco Nexus 5020
|
Cisco Nexus 5020 switches
|
Server Software
|
OS Name and Version
|
Data ONTAP 8.1 Cluster-Mode
|
|
Other Software
|
None
|
|
Filesystem Software
|
Data ONTAP 8.1 Cluster-Mode
|
Server Tuning
|
Name
|
Value
|
Description
|
|
vol modify <volume_name> -atime-update
|
false
|
Disable access time updates (applied to all volumes)
|
Server Tuning Notes
N/A
Disks and Filesystems
|
Description
|
Number of Disks
|
Usable Size
|
|
450GB SAS 15K RPM Disk Drives
|
576
|
191.3 TB
|
|
Total
|
576
|
191.3 TB
|
|
Number of Filesystems
|
single namespace
|
|
Total Exported Capacity
|
96 TB
|
|
Filesystem Type
|
WAFL
|
|
Filesystem Creation Options
|
The file-system was created using default values. An export policy was created giving full-access and applied to the file system.
|
|
Filesystem Config
|
32 RAID-DP(Double Parity) groups of 17 disks each were created across all the disks.
|
|
Fileset Size
|
59769.2 GB
|
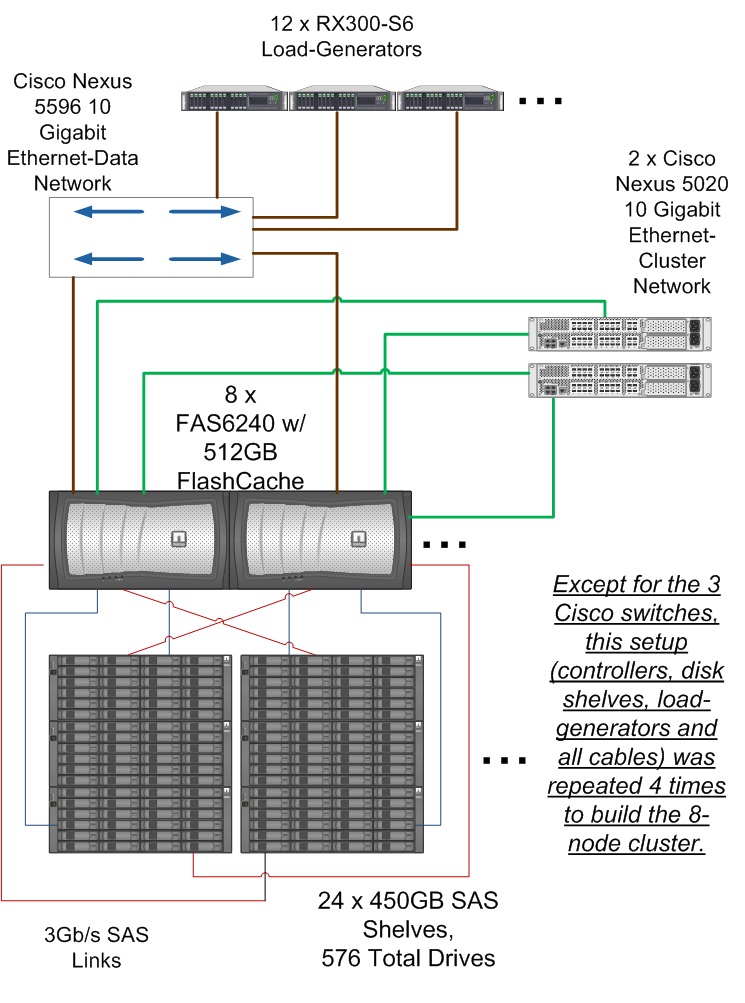
The storage configuration consisted of 8 nodes connected in 4 SFO (storage failover) pairs forming a single cluster. Each node was connected to its own and partner's disks. A single disk pool or "aggregate" was created on each node comprised of 4 RAID-DP raid groups, each composed of 15 data disks and 2 parity disks which held the data for the file-system. A separate aggregate consisting of 3 disks in a single RAID-DP group was created to hold the Data ONTAP operating system files. Each node was allocated a spare disk.A single virtual server or "vserver" was created on the cluster, spanning all physical nodes. A flexible volume was then created on the data aggregate of each node in the cluster. Each volume was junctioned at the root of the single namespace of the vserver. Each volume was striped across all the disks in the data aggregate.
Network Configuration
|
Item No
|
Network Type
|
Number of Ports Used
|
Notes
|
|
1
|
Jumbo frame 10 Gigabit Ethernet
|
24
|
16 ports (2 per node) were used for the cluster network and 8 ports (1 per node) were used for the data network.
|
Network Configuration Notes
The two cluster ports from each node were connected to a pair of Cisco Nexus 5020 switches, one port to each switch to provision the cluster network. This provides high availability for the cluster network in case of port or link failure. One port from each node and each load generator was connected to a Cisco Nexus 5596 switch for the data network. The data and cluster networks were on separate subnets. All the ports (cluster and data) were configured to use jumbo frames.
Benchmark Network
Each load generator was connected to the data network switch via a single 10GbE port. MTU size of 9000 was set for all connections to the switch.
Processing Elements
|
Item No
|
Qty
|
Type
|
Description
|
Processing Function
|
|
1
|
16
|
CPU
|
2.53GHz Intel Xeon(tm) Processor E5540
|
Networking, NFS protocol, WAFL filesystem, RAID/Storage drivers, Clustering
|
Processing Element Notes
Each storage controller has two physical processors and each physical processor is made up of four cores.
Memory
|
Description
|
Size in GB
|
Number of Instances
|
Total GB
|
Nonvolatile
|
|
Storage Controller Main Memory
|
48
|
8
|
384
|
V
|
|
NVRAM Non-volatile Memory on PCIe adapter
|
4
|
8
|
32
|
NV
|
|
Flash Cache Module memory
|
512
|
8
|
4096
|
V
|
|
Grand Total Memory Gigabytes
|
|
|
4512
|
|
Memory Notes
Each storage controller has main memory that is used for the operating system and caching filesystem data. The FlashCache module is a read cache used for caching filesystem data. A separate, integrated battery-backed RAM module is used to provide stable storage for writes that may not have been written to disk.
Stable Storage
The WAFL filesystem logs writes and other filesystem data modifying transactions to the NVRAM adapter. In a storage-failover configuration, as in the system under test, such transactions are also logged to the NVRAM on the partner storage controller so that, in the event of a storage controller failure, any transactions on the failed controller can be completed by the partner controller. Filesystem modifying CIFS/NFS operations are not acknowledged until after the storage system has confirmed that the related data are stored in NVRAM adapters of both storage controllers (when both controllers are active). The battery-backed NVRAM ensures that any uncommitted transactions are preserved for at least 72 hours. In addition, de-staging to Flash on NVRAM preserves these transactions permanently.
System Under Test Configuration Notes
The system under test consisted of 8 FAS6240 storage controllers and 24 storage shelves, each with 24 450GB SAS disk drives. The controllers were running Data ONTAP 8.1 software operating in Cluster-Mode. The 8 storage controllers(nodes) were configured in a storage failover (SFO) configuration and connected to their respective disk shelves in a multi-path high-availability (MPHA) configuration. The SFO was provided by the storage failover software option in conjunction with an InfiniBand interconnect provided on the NVRAM adapter. Each node has physical resources that can be shared across the cluster providing a single namespace. The cluster network (N1) is comprised of 2 Cisco Nexus 5020 switches to provide redundancy. All the nodes in the cluster are connected through the cluster network and all the data throughout the cluster is accessible from any node. The data network (N2) is comprised of a Cisco Nexus 5596 switch. Each node and load-generator have a single 10GbE port connected to this switch. The data and cluster networks are on separate subnets. All ports and interfaces on the data and cluster networks have Jumbo frames enabled.
Other System Notes
All standard data protection features, including background RAID and media error scrubbing, software validated RAID checksum, and double disk failure protection via double parity RAID (RAID-DP) were enabled during the test.
Test Environment Bill of Materials
|
Item No
|
Qty
|
Vendor
|
Model/Name
|
Description
|
|
1
|
12
|
Fujitsu
|
Fujitsu Primergy RX300 S6
|
Fujitsu RX300-S6 rack servers with 48GB memory running RHEL 5.5
|
|
2
|
1
|
Cisco
|
Nexus 5596
|
Cisco Nexus 5596UP Switch
|
Load Generators
|
LG Type Name
|
LG1
|
|
BOM Item #
|
1
|
|
Processor Name
|
Intel Xeon E5645
|
|
Processor Speed
|
2.40GHz
|
|
Number of Processors (chips)
|
2
|
|
Number of Cores/Chip
|
6
|
|
Memory Size
|
48 GB
|
|
Operating System
|
RHEL5.5 Kernel 2.6.18-194.el5
|
|
Network Type
|
10 Gigabit Ethernet
|
Load Generator (LG) Configuration
Benchmark Parameters
|
Network Attached Storage Type
|
NFS V3
|
|
Number of Load Generators
|
12
|
|
Number of Processes per LG
|
224
|
|
Biod Max Read Setting
|
2
|
|
Biod Max Write Setting
|
2
|
|
Block Size
|
AUTO
|
Testbed Configuration
|
LG No
|
LG Type
|
Network
|
Target Filesystems
|
Notes
|
|
1..12
|
LG1
|
Data Network (N2)
|
Single Namespace containing volumes vol1 to vol8
|
See UAR Notes
|
Load Generator Configuration Notes
All clients accessed all mount points. Mount points were assigned to each client in a uniform manner making sure the load is evenly distributed across all clients and all interfaces.
Uniform Access Rule Compliance
For UAR compliance, each flexible volume was mapped to a subdirectory of the global namespace under root (/data1,/data2,...,/data8). Each volume was accessed over all data network interfaces (ip addresses ip1...ip8) such that each volume had a unique mount point on each node. This ensured that 1/8th of the total access on each node was done through a local interface and 7/8th of the total access was done through interfaces which were remote to the node the volume resides on. For these remote accesses, data traversed the cluster network. There were a total of 8 IP addresses available for data access, one per node. Each client mounted all 8 volumes using all 8 target IP addresses, cycling through the IP addresses first for a particular volume and then moving to the next volume after using all IP addresses. Since the total required mount points per client were 224 and the above rotation gave 64 mount points, we circled back to the start of the series and continued till 224 mount points. Each successive client continued from where the previous client left off. For example LG1 was assigned the following mount-point list: ip1:/data1, ip2:/data1,...,ip8:/data1,ip1:/data2,...,ip8:/data2,...,ip1:/data8,...,ip8:/data8,ip1:/data1,..,ip8:/data1,..,ip1:/data4,..,ip8:/data4. LG2 continued from where LG1 left off:ip1:/data5,ip2:/data5,..,ip8:/data5,..,ip8:/data1,..,ip1:/data8,..,ip8:/data8. This was repeated for all 12 clients. This ensured that data access to every volume was uniformly distributed across all clients and target IP addresses. The volumes were striped evenly across all the disks in the aggregate using all the SAS adapters connected to storage backend.
Other Notes
NetApp is a registered trademark and "Data ONTAP", "FlexVol", and "WAFL" are trademarks of NetApp, Inc. in the United States and other countries. All other trademarks belong to their respective owners and should be treated as such.
Config Diagrams
Generated on Tue Nov 01 15:07:16 2011 by SPECsfs2008 HTML Formatter
Copyright © 1997-2008 Standard Performance Evaluation Corporation
First published at SPEC.org on 01-Nov-2011
{kind=link}