SPEC SFS 3.0 (SFS97_R1) is the latest version of the Standard Performance Evaluation Corp.'s benchmark that measures NFS file server throughput and response time. It provides a standardized method for comparing performance across different vendor platforms. This is an incremental release that based upon the design of SFS 2.0 (SFS97) and address several critical problems uncovered in that release, additional it addresses several tools issues and revisions to the run and reporting rules.
The major features of SPEC SFS 3.0 (SFS97_R1) include:
This document specifies the guideline on how SPEC SFS 3.0 is to be run for measuring and publicly reporting performance results. These rules have been established by the SPEC SFS Subcommittee and approved by the SPEC Open Systems Steering Committee. They ensure that results generated with this suite are meaningful, comparable to other generated results, and are repeatable. Per the SPEC license agreement, all results publicly disclosed must adhere to these Run and Reporting Rules.
This document also includes the background and design of the SFS benchmark and a guide to using the SFS tools.
SPEC released SFS 1.0 in 1993. In November of 1994 SFS 1.1 was released which fixed a set of minor problems. Version 1.X of the SFS benchmark and its related work load were commonly referred to as LADDIS [Wittle]. SFS 1.X contains support for measuring NFS version 2 servers with the UDP network transport. With the advance of NFS server technology and the continuing change in customer workloads, SPEC has updated SFS 1.1 to reflect these changes. SFS 2.0, released in December of 1997, reflects the efforts of SPEC in this regard. With the release of SFS 2.0, the LADDIS name was replaced with the preferred name of SPECsfs97.
The SPECsfs benchmark is a synthetic benchmark that generates an increasing load of NFS operations against the server and measures the response time (which degrades) as load increases. The older version, SFS 1.1, only supports NFS version 2 over UDP for results generation. SFS 2.0 added support for NFS version 3 server measurements. SFS 2.0 also added support for the use of TCP as a network transport in generating benchmark results. The SPECsfs workload consists primarily of the mix of NFS operations, the file set, block size distribution, and the percentage of writes which are appends versus overwrites. The single workload in SFS 1.1 measured NFS Version 2 over UDP and presented the server with a heavy write-oriented mix of operations (see Table 1). The 15% WRITE component for NFS was considered high, and WRITE activity dominated processing on most servers during a run of the SFS 1.1 work load. The operation mix for the SFS 1.1 workload was obtained primarily from nhfsstone (a synthetic NFS Version 2 benchmark developed by Legato Systems). Block size and fragment distributions were derived from studies at Digital. Append mode writes accounted for 70% of the total writes generated by the workload. In SFS 1.1, 5MB per NFS op/s of data was created to force increasing disk head motion when the server misses the cache and 1MB per NFS op/s was actually accessed (that is 20% of the data created was accessed at any point generated). The 1MB of data accessed per NFS op/s was accessed according to a Poisson distribution to provide a simulation of more frequently accessed files.
| NFS Operation |
SFS 1.1 NFSv2 |
SFS 2.0 & 3.0 NFSv2 |
SFS 2.0 & 3.0 NFSv3 |
|---|---|---|---|
| LOOKUP | 34% | 36% | 27% |
| READ | 22% | 14% | 18% |
| WRITE | 15% | 7% | 9% |
| GETATTR | 13% | 26% | 11% |
| READLINK | 8% | 7% | 7% |
| READDIR | 3% | 6% | 2% |
| CREATE | 2% | 1% | 1% |
| REMOVE | 1% | 1% | 1% |
| FSSTAT | 1% | 1% | 1% |
| SETATTR | 1% | ||
| READDIRPLUS | 9% | ||
| ACCESS | 7% | ||
| COMMIT | 5% |
SFS 2.0 supported both NFS version 2 and NFS version 3. The results for each version were not comparable. The NFS Version 2 mix was derived from NFS server data. The NFS Version 3 mix was desk-derived from the NFS Version 2 mix. Neither of these workloads were comparable to the SFS 1.1 work load.
From SFS 1.1, there were two main areas of change in the workload generated by the benchmark. To determine the workload mix, data was collected from over 1000 servers over a one month period. Each server was identified as representing one of a number of environments, MCAD, Software Engineering, etc. A mathematical cluster analysis was performed to identify a correlation between the servers. One cluster contained over 60% of the servers and was the only statistically significant cluster. There was no correlation between this mix and any single identified environment. The conclusion was that the mix is representative of most NFS environments and was used as the basis of the NFS version 2 workload. Due to the relatively low market penetration of NFS version 3 (compared to NFS version 2), it was difficult to obtain the widespread data to perform a similar data analysis. Starting with the NFS version 2 mix and using published comparisons of NFS version 3 and NFS version 2 given known client workloads [Pawlowski], the NFS version 3 mix was derived and verified against the Sun Microsystems network of servers.
The file sets in the SFS 2.0 and workloads were modified so that the overall size doubled as compared to SFS 1.1 (10 MB per ops/s load requested load). As disk capacities have grown, so has the quantity of data stored on the disk. By increasing the overall file set size a more realistic access pattern was achieved. Although the size doubled, the percentage of data accessed was cut in half resulting in the same absolute amount of data accessed. While the amount of disk space used grew at a rapid rate, the amount actually accessed grew at a substantially slower rate. Also the file set was changed to include a broader range of file sizes (see table 2 below). The basis for this modification was a study done of a large AFS distributed file system installation that was at the time being used for a wide range of applications. These applications ranged from classic software development to administrative support applications to automated design applications and their data sets. The SFS2.0 file set included some very large files which are never actually accessed but which affect the distribution of files on disk by virtue of their presence.
There is no change in the mix of operations in SFS 3.0. (See TABLE 1 above) The mix is the same as in SFS 2.0. However, the results for SFS 3.0 are not comparable to results from SFS 2.0 or SFS 1.1. SFS 3.0 contains changes in the working set selection algorithm that fixes errors that were present in the previous versions. The selection algorithm in SFS 3.0 accurately enforces the originally defined working set for SFS 2.0. Also enhancements to the workload mechanism improve the benchmark's ability to maintain a more even load on the SUT during the benchmark. These enhancements affect the workload and the results. Results from SFS 3.0 should only be compared with other results from SFS 3.0.
The files selected by SFS 3.0 are on a "best fit" basis, instead of purely random as with SFS 1.1. The "best fit" algorithm in SFS 2.0 contained an error that prevented it from working as intended. This has been corrected in SFS 3.0.
SFS 3.0 contains changes in the working set selection algorithm that fix errors that were present in the previous versions. The file set used in SFS 3.0 is the same file set as was used in SFS 2.0 with algorithmic enhancements to eliminate previous errors in the file-set selection mechanism. The errors in previous versions of SFS often reduced the portion of the file-set actually accessed, which is called the "working set".
| Percentage | Filesize |
|---|---|
| 33% | 1KB |
| 21% | 2KB |
| 13% | 4KB |
| 10% | 8KB |
| 8% | 16KB |
| 5% | 32KB |
| 4% | 64KB |
| 3% | 128KB |
| 2% | 256KB |
| 1% | 1MB |
There are several areas of change in the SPEC SFS 3.0 benchmark. The changes are grouped into the following areas:
Within each of these areas there is a brief description of what motivated the change along with a detailed description of the new mechanisms.
Gettimeofday() resolution.
In the SFS 2.0 benchmark time was measured with the gettimeofday() interface. The function gettimeofday() was used to measure intervals of time
that were short in duration. SFS 3.0 now measures the resolution of the gettimeofday() function
to ensure its resolution is sufficient to measure these short events. If the
resolution of gettimeofday() is 100 microseconds or better then the
benchmark will proceed. If it is not then the benchmark will log the resolution
and terminate. The user must increase the resolution to at least 100 microseconds
before the benchmark will permit the measurement to continue.
Select() resolution compensation.
In the SFS benchmark there is a regulation mechanism that establishes a steady
workload. This regulation mechanism uses select() to introduce sleep intervals on the clients.
This sleep interval is needed if the client is performing more requests than
was intended. In SFS 2.0 the regulation mechanism relied on select() to suspend the client for the specified number
of microseconds. The last parameter to select is a pointer to a timeval structure.
The timeval structure contains a field for seconds and another field for
microseconds. The implementation of select may or may not provide microsecond
granularity. If the requested value is less than the granularity of the implementation
then it is rounded up to the nearest value that is supported by the system.
On many systems the granularity is 10 milliseconds. The mechanism in SFS
2.0 could fail if the granularity of the select() call
was insufficient. It was possible that the benchmark could attempt to slow
the client by a few milliseconds and have the unintended effect of slowing
the client by 10 milliseconds or more. The SFS 2.0 benchmark makes adjustments
to the sleep interval at two different times during the benchmark. During
the warm-up phase the benchmark makes adjustments every 2 seconds. In the
run phase it makes adjustments every 10 seconds. Once the adjustment was
made the adjustment value was used for the rest of the interval (2 seconds
or 10 seconds) until the next time the adjustment was recalculated. If the
granularity of select's timeout was insufficient
then the sleep duration would be incorrect and would be used for the entire
next interval.
The mechanism used in SFS 3.0 is more complex. The sleep interval is calculated as it was in SFS 2.0. When the client is suspended in select() and re-awakens it checks the amount of time that has passed using a the gettimeofday() interface. This allows the client to know if the amount of time that it was suspended was the desired value. In SFS 3.0 the requested sleep interval is examined with each NFS operation. If the requested sleep interval was for 2 milliseconds and the actual time that the client slept was 10 milliseconds then the remaining 8 milliseconds of extra sleep time is remembered in a compensation variable. When the next NFS operation is requested and goes to apply the sleep interval of 2 milliseconds the remaining 8 milliseconds is decremented by the requested 2 milliseconds and no actual sleep will be performed. Once the remainder has been consumed then the process begins again. This mechanism permits the client to calculate and use sleep intervals that are smaller than the granularity of the select() system call. The new mechanism performs these compensation calculations on every NFS operation.
The gettimeofday() interface measures wall clock interval that the process was suspended by select(). This interval may occasionally include periods of time that were unrelated to select(), such as context switches, cron jobs, interrupts, and so on. SFS 3.0 resets the compensation variable whenever it reaches 100 milliseconds, so that noise from unrelated events does not overload the compensation mechanism.
The SFS 2.0 benchmark uses a mechanism to establish a steady workload. This mechanism calculates the amount of work that needs to be completed in the next interval. It calculates the amount of sleep time (sleep duration per NFS operation) that will be needed for each operation so that the desired throughput will be achieved. During the warm-up phase the interval for this calculation is every 2 seconds. During the run phase the interval for this calculation is every 10 seconds. If the client performs more operations per second than was desired then the sleep duration for each NFS operation over the next interval is increased. In SFS 2.0 the sleep duration for each NFS operation could be increased too quickly and result in the client sleeping for the entire next. This resulted in no work being performed for the entire next interval. When the next interval completed then the algorithm in SFS 2.0 could determine that it needed to decrease the sleep duration for the next interval. The next interval would perform work and could then again have performed too much work and once again cause the next sleep duration calculation to overshoot and cause the next interval to perform no work. This oscillation could continue for the duration of the test.
In SFS 3.0 the new sleep interval is restricted to be no more than:
2 * (previous_sleep_interval +5) Units are in milliseconds
This reduces how aggressively the algorithm increments the sleep interval and permits the steady workload to be achieved. In SFS 2.0 the calculation for how much work to perform in the next interval would attempt to catch up completely in the next interval. This has been changed so that the sleep duration will not change to rapidly.
SFS 3.0 also checks the quantity of work to be performed for each interval, in the run phase, and if any interval contains zero operations then the benchmark logs an error and terminates.
Working set and file distribution
In order to understand the changes in the SFS 3.0 benchmark there is need for the reader to become familiar with several internal mechanisms in SFS 2.0. The following is a brief description of these mechanisms. The following graphic is provided to assist in understanding the overall file distribution of SFS.
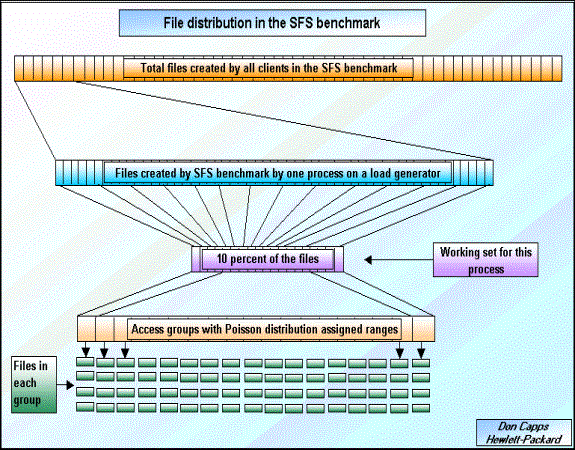
The SFS benchmark creates files that will later be used for measurement of the system's performance. The working set of the SFS benchmark is 10 percent of all of the files that it creates. This working set is established when the benchmark initializes. This initialization groups the files in the working set into access groups. Each group contains the same number of files. For each group there is a probability of access that is calculated using a Poisson distribution for all of the groups. The use of a Poisson distribution simulates the access behavior of file servers. That behavior being that some files are accessed more frequently than others. The Poisson probability is used to create a range value that each group encompasses. The range value for each group is the Poisson probability * 1000 + previous_groups_range_value. For groups with a low probability the range value is incremented by a small number. For groups with a high probability the range value is incremented by a large number. During the run phase each NFS operation selects one of the files in the working set to be accessed. Since the time to select the file is inside the measurement section it is critical that the file selection mechanism be as non-intrusive as possible. This selection mechanism uses a random number that is less than or equal to the maximum range value that was calculated for all the groups. A binary search of the group's ranges is performed to select the group that corresponds to this random value. After the group is selected then another random number is used to select a particular file within the group.
The following is a graphical representation of the SFS 2.0 Poisson distribution that would be used when the operations/second/process is 25. This results in 12 access groups with the access distribution seen below.

The problem with SFS 2.0 is that the Poisson distribution could deteriorate as the number of files being accessed by any process became large. The probabilities for some of the access groups became zero due to rounding. The following is a graphical representation of the SFS 2.0 Poisson distribution that would be used when the operations/sec/process is increased and there are 192 access groups.
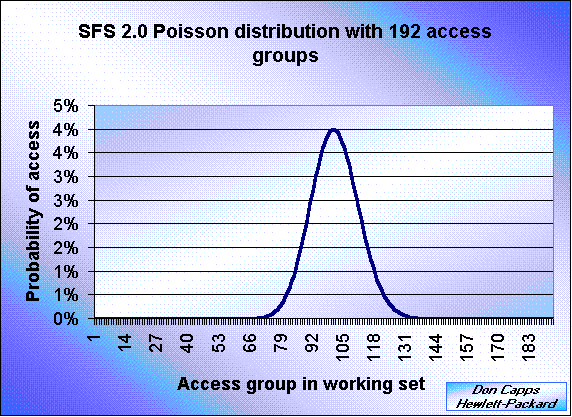
In SFS 2.0 the number of files in the working set is reduced as the number of operations/sec/proc is increased. The algorithm also contained a mathematical error that could eventually reduce the number of access groups to one. This was not seen in any previous results as the criteria to activate this defect was that the number of operations/second/process would need to be above 500 and no previous results were in this range. For more details on each defect in SFS 2.0 see the "Defects in SFS 2.0" written by Stephen Gold from Network Appliance on the SPEC web site.
The defects in SFS 2.0 resulted in an overall reduction in the working set and may have impacted the SPECsfs97 results. The exact impact on the result depends on the size of the caches in the server and other factors. If the caches were sufficiently large as to encompass the entire 10 percent of all of the files that were created (the intended working set) then the impact on the result may be negligible. This is because if all of the files that should have been accessed would have fit in the caches then the selection of which file to access becomes moot.
In SFS 3.0 the file selection algorithm has been changed so that reduction of the working set no longer occurs. The algorithm in SFS 3.0 is based on the Poisson probabilities used in SFS 2.0, but SFS 3.0 manipulates the probabilities to ensure that all of the files in the working set have a reasonable probability of being accessed.
To achieve this, SFS 3.0 implements a "cyclical Poisson" distribution. The following graph shows the SFS 3.0 access probabilities for 192 access groups:
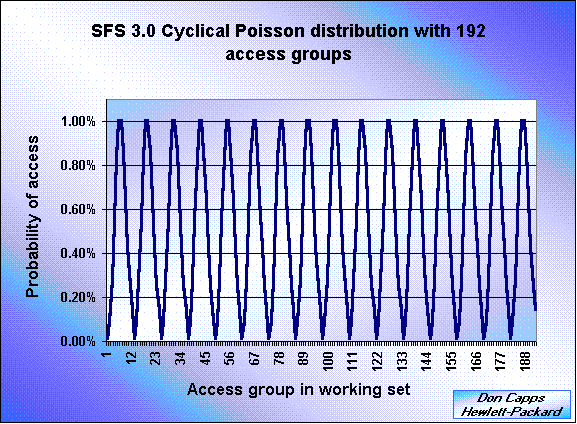
Instead of varying the parameter of the Poisson distribution to generate values for 192 access groups, the relative probabilities for 25 ops/sec (12 access groups) are simply repeated as many times as necessary. Thus there are no access groups with extremely small probabilities, and no huge floating-point values are needed to compute them.
For 192 access groups, a total of 16 repetitions or "cycles" are used. Each cycle of access groups has the same aggregate probability of access, namely 1/16. (The number of access groups in SFS 3.0 is always a multiple of 12, so there are no partial cycles.)
The Poisson probabilities for 25 ops/sec (12 access groups) are scaled down by 16 (the number of cycles) and applied to the first 12 access groups, which constitute the first cycle of the distribution. The same probabilities are also applied to the next 12 access groups (the second cycle) and the process is repeated across all 16 cycles.
Another view of the working set is to divide it into 12 distinct access-group "generations", each of which is represented by a single access group in each cycle. Within a given generation, all the access-groups have the same probability of access. For instance, groups 1, 13, 25, ... 181 constitute one generation.
The cache profile across 192 groups looks very much like the cache profile across 12 groups. Why is this the case? The answer is that the cyclical Poisson distribution results in the following distribution of accesses across generations:
In the above graph there are still 192 access groups, but they have been aggregated together into 12 generations. The probability of access for each generation has been plotted. Note that the curve for 192 access groups (with 16 access groups per generation) looks the same as the one for 12 access groups (with one access group per generation).
Hence the cache behavior of SFS is no longer sensitive to the number of load-generating processes used to achieve a given request rate.
In theory, the same effect could have been achieved by always having 12 access groups, no matter how many files there are. This was not done for fear that exhaustive searches for files within a very large access group would be expensive, causing the load-generators to bog down in file selection.
Support for Linux & BSD clients
The SFS 3.0 benchmark contains support for Linux and BSD clients. As the
popularity of these other operating systems continues to grow the demand for
their support was seen as an indication of the importance of SFS support.
Best fit algorithm
In SFS 2.0 after a access group was selected for access, a file was selected
for access. This selection was done by picking a random file within the group
to be accessed and then searching for a file that meets the transfer size criteria.
There was an attempt to pick a file based on the best fit of transfer size
and available file sizes. This mechanism was not working correctly due to an
extra line of code that was not needed. This defect resulted in the first file
to have a size equal to or larger than the transfer size being picked. SFS
3.0 eliminates the extra line of code and permits the selection to be a best
fit selection instead of a first fit selection.
New submission tools
The "generate" script is now included with SFS 3.0. This shell
script is used to create the submission that is sent to SPEC for review and
publication of SFS results.
Readdirplus() enhancements.
In SFS 2.0 the benchmark tested the Readdirplus() functionality of NFS version
3. However it did not validate that all of the requested data was returned
by the operation. SFS 3.0 performs the additional validation and ensures
that all of the requested attributes and data are returned from the Readdirplus() operation.
Bug fixes.
Source and build changes for portability
Shell-script changes for portability
Documentation changes in SFS 3.0
The SFS 3.0 Users Guide has been updated to reflect: